
Las redes generativas adversarias (GANs) [1] son una familia de modelos generativos de variable latente, , que constituyó el estado del arte en la generación de imágenes hasta la llegada de los modelos de difusión. A diferencia de otros paradigmas, las GANs no modelan explícitamente la densidad , sino que aprenden directamente un procedimiento para generar muestras desde sin tener que evaluar dicha densidad. Esta característica clasifica a las GANs como modelos generativos implícitos [2], los cuales no pueden ser entrenados por enfoques que involucren la verosimilitud ya que no conocen . Si bien hay varios enfoques para evitar trabajar con la verosimilitud, las GANs utilizan un mecanismo de entrenamiento adversarial entre dos redes neuronales. En este capítulo se formulará e implementará una GAN básica, se introducirá la convolución transpuesta como bloque básico para el upsampling de los generadores, y se revisarán algunas de las arquitecturas neuronales más representativas de la tarea de generación de imágenes con GANs. Por otro lado, más allá del valor histórico de estos modelos, varias de las técnicas que se introdujeron aquí siguen siendo relevantes para el diseño de arquitecturas neuronales para otros paradigmas como los modelos de difusión.
Formulación de una GAN
Modelo generativo implícito
La red bayesiana asociada a una GAN es la red bayesiana de variable latente estándar, , donde el prior latente se suele elegir como una distribución de la que es fácil generar muestras (e.g., , aunque también se puede utilizar la distribución uniforme). En cambio, para la parte generadora , esta viene dada por una transformación determinista de a través de una red neuronal (denominada generador), es decir:
De esta forma, es una distribución que concentra toda su masa en el punto (i.e., la única muestra que puede obtenerse desde es ). Esta es una primera diferencia con respecto a otros modelos generativos, donde lo usual es fijar distribuciones pertenecientes a alguna familia paramétrica (e.g., gaussianas o categóricas), y usar una red neuronal para aprender sus parámetros en vez de aprender directamente la transformación .
Discriminador y entrenamiento adversarial
Para entrenar la red neuronal sin acceso a la función de verosimilitud, , una GAN introduce un clasificador binario auxiliar, , denominado discriminador, cuya tarea es distinguir si una muestra proviene de la distribución de datos (, real) o de la distribución implícita (, sintética). Naturalmente, el modelo discriminativo se elige como un clasificador binario estándar:
donde es otra red neuronal independiente de . Mientras se entrena para clasificar correctamente, se entrena para engañarlo, lo que fuerza, como subproducto, a que genere muestras similares a .
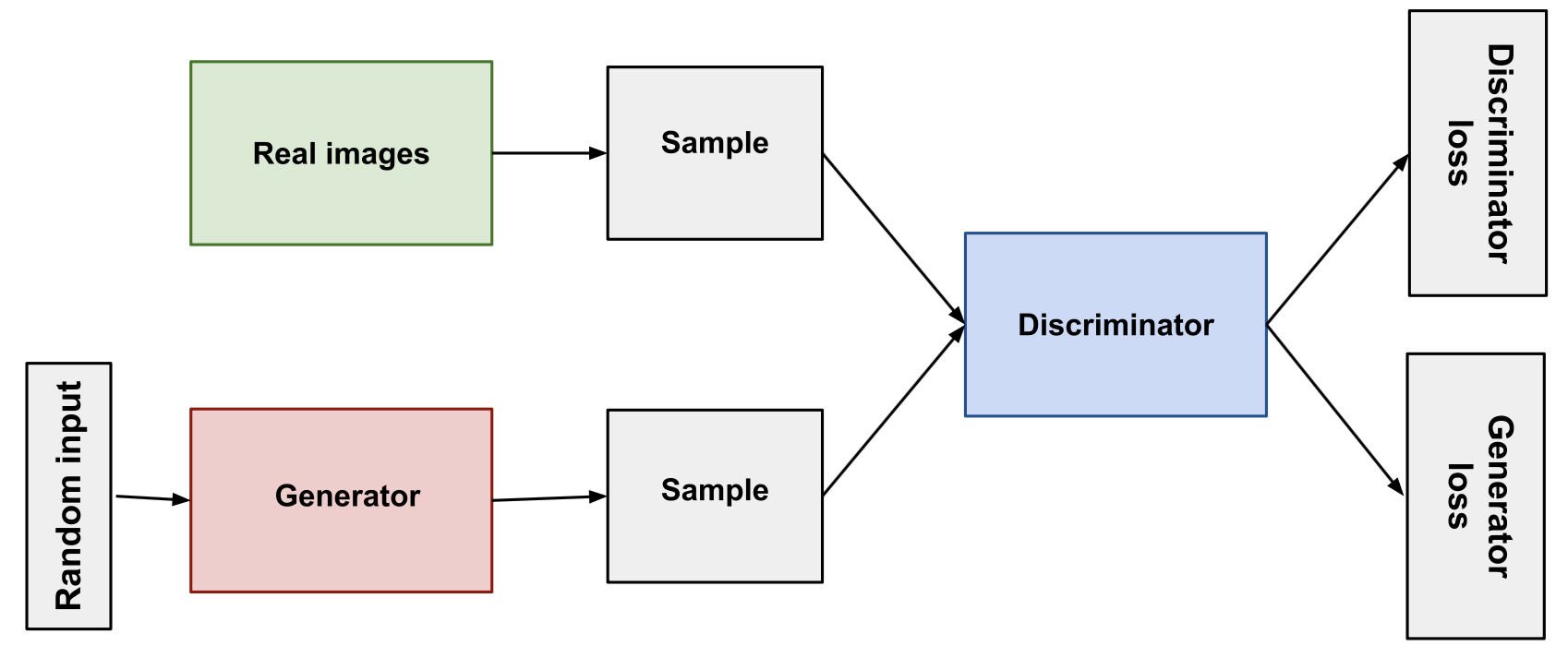
Diagrama de entrenamiento de una GAN. Imagen obtenida desde [3].
Es importante destacar que no forma parte del modelo generativo; es solo un mecanismo de entrenamiento que se descarta una vez finalizado el ajuste del generador. La GAN, vista como modelo, sigue siendo una única red bayesiana .
Función objetivo
Dado que es un clasificador, su entrenamiento se puede realizar siguiendo el criterio de máxima verosimilitud sobre una distribución conjunta de pares formados por imágenes reales (generadas desde ; ) e imágenes sintéticas (generadas desde ; ). Si las muestras reales y sintéticas se utilizan de forma balanceada en el entrenamiento, esta distribución es
Desarrollando la log-verosimilitud del clasificador :
por lo que . En consecuncia, la función objetivo de una GAN es:
Recordando que el discriminador (clasificador) busca maximizar su rendimiento y el generador busca que el discriminador que se equivoque, el entrenamiento de una GAN consiste en optimizar el siguiente juego minimax:
En la práctica, las esperanzas se aproximan mediante estimaciones de Monte Carlo. La primera se estima con un conjunto de entrenamiento de muestras i.i.d. desde , mientras que la segunda se estima generando muestras i.i.d. desde .
Por otro lado, es usual escribir la función objetivo de manera separada para cada red neuronal dado que muchas veces se suele modificar una (o ambas) funciones objetivo:
donde se han omitido los factores y el término constante para en la verosimilitud.
Notar que esta función objetivo es saturante (en el sentido de que sufre de vanishing gradients), lo que es particularmente malo durante el comienzo del entrenamiento ya que en esta etapa el generador es muy débil, por lo que el discriminador puede diferenciar fácilmente una muestra real de una falsa. En consecuencia, al comienzo del entrenamiento, , por lo que el gradiente de respecto a es muy pequeño, lo que dificulta el aprendizaje.
Para resolver esto, en la práctica se entrena el generador minimizando una función de pérdida no saturante:
Esta función de pérdida busca maximizar la probabilidad de que el discriminador clasifique las muestras falsas como reales, manteniendo el objetivo inicial del generador, pero otorgándole gradientes útiles a la red neuronal .
En la siguiente figura se puede ver la diferencia entre ambas curvas, en función de la salida del discriminador, :
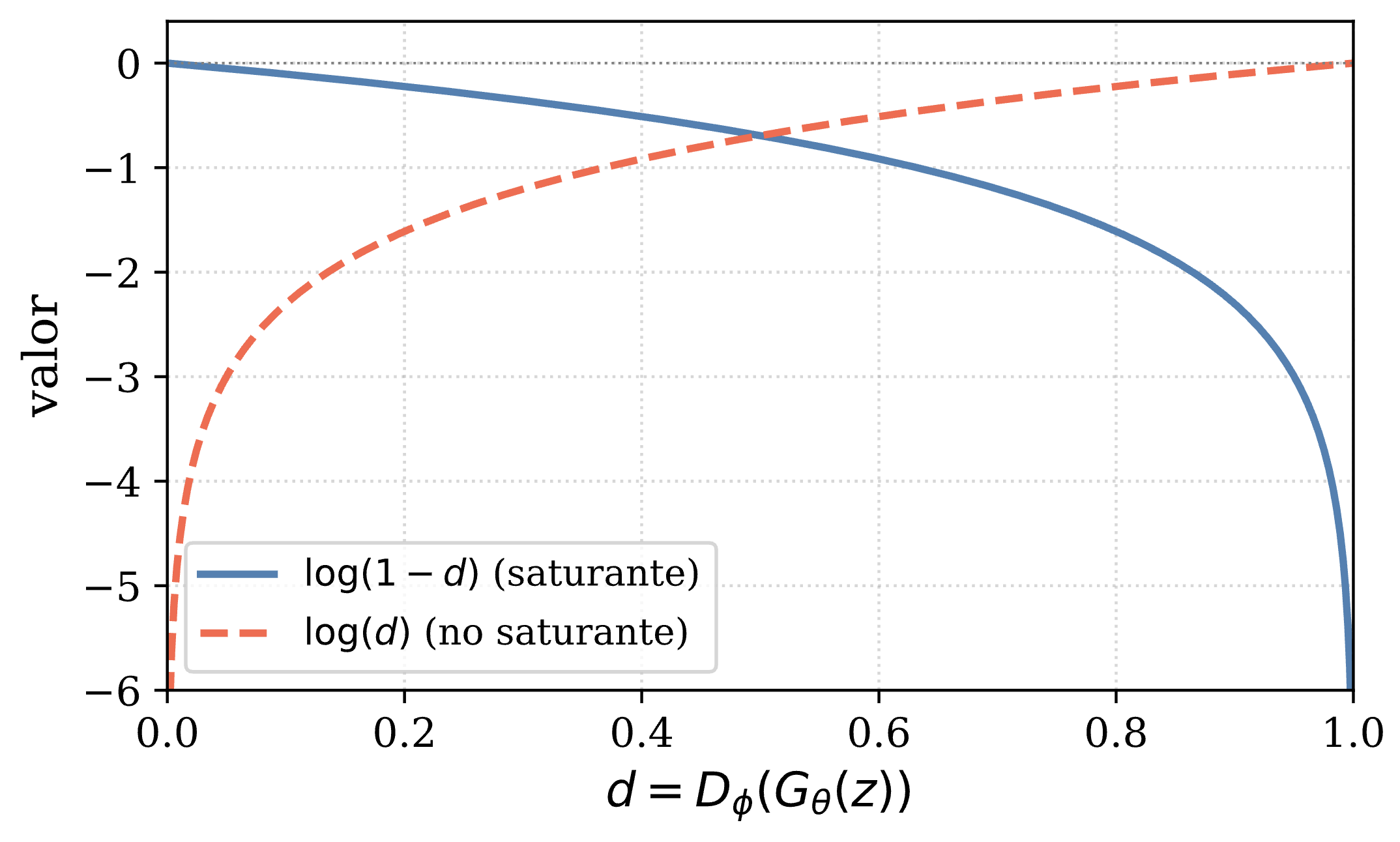
Función objetivo saturante y no saturante. Se observa que al comienzo del entrenamiento (cuando ), la derivada de la función saturante es casi nula.
Respecto al entrenamiento basado en el juego minimax, en cada iteración se comienza optimizando los parámetros del discriminador varias veces (parte ), y luego se actualizan los parámetros del generador una vez (parte ). Esta estrategia, en la que el discriminador se entrena más que el generador, busca mantener al discriminador en un estado cercano al óptimo durante el entrenamiento, lo que proporciona señales de gradiente más confiables para el generador. Si el discriminador se debilita demasiado y pierde capacidad para distinguir entre datos reales y generados, el generador deja de recibir feedback útil durante el entrenamiento.
Implementación sobre datos bidimensionales
Para fijar la formulación se entrenará una GAN sobre un dataset bidimensional (). Las librerías que se utilizarán son las siguientes:
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.datasets import make_swiss_rollComo distribución de datos se utiliza el dataset make_swiss_roll de scikit-learn [4], proyectado a , con ruido gaussiano de baja varianza para añadir variabilidad:
def get_batch(batch_size=1000, noise=0.1):
x, _ = make_swiss_roll(batch_size, noise=noise)
x = x[:, [0, 2]]
x = (x - x.mean()) / x.std()
return torch.tensor(x).float()
# Ejemplo:
samples = get_batch()
plt.figure(figsize=(3, 3))
plt.scatter(samples[:, 0], samples[:, 1], s=1)
plt.show()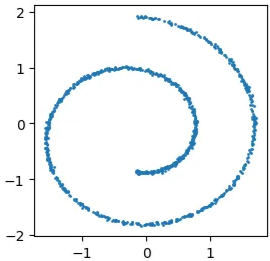
Muestras del dataset swiss roll proyectado a .
Para las redes neuronales y se utilizarán dos redes fully connected de cuatro capas. Como dimensión latente se considerará . Si bien lo usual es considerar (considerando la hipótesis de la variedad), en este ejemplo se considerará que para no colapsar la capacidad de la red neuronal del generador:
data_dim, latent_dim = 2, 16
generator = nn.Sequential(
nn.Linear(latent_dim, 32), nn.ReLU(),
nn.Linear(32, 64), nn.ReLU(),
nn.Linear(64, 128), nn.ReLU(),
nn.Linear(128, data_dim)
)
discriminator = nn.Sequential(
nn.Linear(data_dim, 128), nn.ReLU(),
nn.Linear(128, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU(),
nn.Linear(32, 1), nn.Sigmoid()
)Por la naturaleza competitiva entre y , las GANs suelen presentar una dinámica de entrenamiento inestable, lo que ha motivado el uso hiperparámetros que se sabe, principalmente por experiencia empírica, que funcionan bien. En este caso se utilizará Adam [5] con betas=(0.5, 0.999), una elección común sugerida por DCGAN (revisada más abajo):
def train(generator, discriminator, latent_dim, iters=5000):
# Optimizadores:
generator_optimizer = optim.Adam(generator.parameters(), betas=(0.5, 0.999))
discriminator_optimizer = optim.Adam(discriminator.parameters(), betas=(0.5, 0.999))
for iter in range(iters):
# Datos de entrenamiento:
x_true = get_batch()
x_fake = generator(torch.randn([len(x_true), latent_dim]))
# Entrenamiento discriminador:
loss_y1 = torch.log(discriminator(x_true)).mean()
loss_y0 = torch.log(1-discriminator(x_fake.detach())).mean()
loss_discriminator = - 1 / 2 * (loss_y1 + loss_y0)
discriminator_optimizer.zero_grad()
loss_discriminator.backward()
discriminator_optimizer.step()
# Entrenamiento generador (versión saturante):
loss_generator = 1 / 2 * torch.log(1-discriminator(x_fake)).mean()
generator_optimizer.zero_grad()
loss_generator.backward()
generator_optimizer.step()train(generator, discriminator, latent_dim)Una vez entrenado el modelo, se pueden generar nuevas muestras mediante ancestral sampling sobre la red bayesiana sampleando desde , y luego evaluando :
def generate_samples(n_samples=1000):
z = torch.randn([n_samples, latent_dim])
samples = generator(z).detach()
return samples
samples = generate_samples()
plt.figure(figsize=(3, 3))
plt.scatter(samples[:, 0], samples[:, 1], s=1)
plt.show()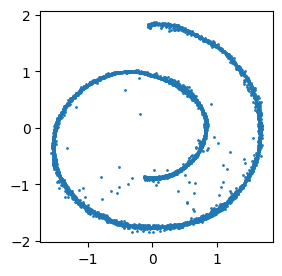
Muestras generadas por la GAN entrenada.
Se observa que el generador aprendió a reproducir, aproximadamente, la distribución a pesar de no haber modelado explícitamente .
Observación 1.
En la implementación anterior se incluyó una sigmoide en la salida del discriminador para que su rango sea . Una práctica más estable numéricamente es eliminar la sigmoide y trabajar directamente con los logits, usando nn.BCEWithLogitsLoss para el cálculo de la pérdida. La equivalencia con esta función de pérdida es directa al identificar la entropía cruzada (binaria) en la verosimilitud , por lo que:
Notar que esto es análogo a lo que se realiza con los modelos de lenguaje, donde usualmente no se incluye un módulo nn.Softmax en la salida del Transformer y se utiliza nn.CrossEntropyLoss para el equivalencia con la verosimilitud de una distribución categórica sobre el vocabulario.
Generación condicional
Al igual que toda red bayesiana, la formulación anterior se puede extender al caso condicional considerando una variable adicional que guíe la generación. La red bayesiana de una GAN condicional (CGAN) [6] se factoriza como , donde implícitamente se ha asumido que (i.e., el prior latente es independiente del factor condicionante). Además, tanto el generador, , como el discriminador, , ahora reciben la condición como entrada adicional. Con estos cambios, la función objetivo de una CGAN es:
donde es una distribución sobre que no es modelada ni aprendida (los valores de son sampleados durante el entrenamiento). La forma en la que se inyecta en las redes neuronales depende de su naturaleza:
Etiqueta de clase . Lo más simple es concatenar el valor de a las entradas. Una opción más expresiva es utilizar una matriz de embedding , de forma análoga a los modelos de lenguaje, donde la -ésima fila de es un vector aprendido asociado a la clase . Para evitar parámetros adicionales se puede usar el vector one-hot de cada clase como embedding fijo.
Texto . Una opción simple y efectiva es pasar la secuencia de tokens por un modelo de embeddings preentrenado como CLIP, BERT o T5, y utilizar el vector resultante como entrada adicional al generador. Una alternativa más sofisticada, utilizada por modelos como Stable Diffusion [7], consiste en inyectar la secuencia de embeddings mediante atención cruzada en bloques específicos de la red.
Imagen . Para tareas image-to-image (e.g., colorización, super-resolución, inpainting) es usual utilizar arquitecturas especializadas como la U-Net (revisada más abajo). Además, para mezclar texto con imagen, se pueden usar arquitecturas más sofisticadas como la usada por FLUX (modelo de flow matching), donde se trabajan tokens de imagen de forma similar.
Implementación para MNIST
A modo de ejemplo, se implementará una CGAN sobre el dataset MNIST, donde la condición será el dígito asociado a la imagen. Se comenzará instanciando el dataset con las imágenes normalizadas al intervalo (otra recomendación de DCGAN):
transform = transforms.Compose([
transforms.ToTensor(), # normalización [0, 1].
transforms.Normalize((0.5,), (0.5,)) # normalización [-1, 1].
])
dataset = datasets.MNIST(root='data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=128, shuffle=True, drop_last=True, num_workers=2)
# Ejemplo:
fig, axes = plt.subplots(1, 10, figsize=(10, 1.2))
for cond in range(10):
idx = (dataset.targets == cond).nonzero()[0].item()
x, cond_true = dataset[idx]
img = x.permute(1, 2, 0) * 0.5 + 0.5 # desnormalización a [0, 1].
axes[cond].imshow(img, cmap='gray_r')
axes[cond].set_title(cond_true)
axes[cond].axis('off')
plt.show()
Muestras de MNIST con sus respectivas etiquetas.
Como redes neuronales se utilizarán MLPs simples, dejando el estudio de las arquitecturas convolucionales para la siguiente sección. Para el generador:
class Generator(nn.Module):
def __init__(self, data_dim, n_classes, cond_embed_dim, latent_dim):
super().__init__()
self.cond_embed = nn.Embedding(n_classes, cond_embed_dim)
self.net = nn.Sequential(
nn.Linear(latent_dim + cond_embed_dim, 256), nn.BatchNorm1d(256), nn.LeakyReLU(0.2),
nn.Linear(256, 512), nn.BatchNorm1d(512), nn.LeakyReLU(0.2),
nn.Linear(512, 1024), nn.BatchNorm1d(1024), nn.LeakyReLU(0.2),
nn.Linear(1024, data_dim), nn.Tanh()
)
self.apply(self._init_weights)
@staticmethod
def _init_weights(m):
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0.0, 0.02)
nn.init.zeros_(m.bias)
def forward(self, z, cond):
cond = self.cond_embed(cond)
input = torch.cat([z, cond], dim=1)
return self.net(input)Notar que se utilizaron heurísticas como inicialización de parámetros y uso de capas de normalización. Como se verá en las siguientes secciones, estas modificaciones permiten tener un entrenamiento más estable.
Para el discriminador se utilizará una red análoga, donde no se incluye nn.Softmax en la salida para trabajar con nn.BCEWithLogitsLoss:
class Discriminator(nn.Module):
def __init__(self, data_dim, n_classes, cond_embed_dim):
super().__init__()
self.cond_embed = nn.Embedding(n_classes, cond_embed_dim)
self.net = nn.Sequential(
nn.Linear(data_dim + cond_embed_dim, 1024), nn.LeakyReLU(0.2), nn.Dropout(0.3),
nn.Linear(1024, 512), nn.LeakyReLU(0.2), nn.Dropout(0.3),
nn.Linear(512, 256), nn.LeakyReLU(0.2), nn.Dropout(0.3),
nn.Linear(256, 1)
)
self.apply(self._init_weights)
@staticmethod
def _init_weights(m):
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0.0, 0.02)
nn.init.zeros_(m.bias)
def forward(self, x, cond):
cond = self.cond_embed(cond)
input = torch.cat([x.flatten(1), cond], dim=1)
return self.net(input)Para el entrenamiento, ahora se utilizará la función de pérdida no saturante (recomendación de la GAN original). Además, se utilizará label smoothing para el discriminador (similar a lo hecho en ARMs), lo que ayuda a evitar la saturación y mejorar la estabilidad del entrenamiento:
def train(generator, discriminator, latent_dim, epochs=50, label_smoothing=0.9, g_steps=2):
generator.to(DEVICE).train()
discriminator.to(DEVICE).train()
# Optimizadores:
generator_optimizer = optim.Adam(generator.parameters(), lr=2e-4, betas=(0.5, 0.999))
discriminator_optimizer = optim.Adam(discriminator.parameters(), lr=2e-4, betas=(0.5, 0.999))
criterion = nn.BCEWithLogitsLoss()
losses = {'generator': [], 'discriminator': []}
try:
for epoch in tqdm(range(epochs)):
for x_true, cond_true in dataloader:
batch_size = len(x_true)
ones = torch.ones(batch_size, 1, device=DEVICE)
zeros = torch.zeros(batch_size, 1, device=DEVICE)
# Datos de entrenamiento:
# - True:
cond_true = cond_true.to(DEVICE)
x_true = x_true.to(DEVICE)
# - Fake:
z = torch.randn(batch_size, latent_dim, device=DEVICE)
x_fake = generator(z, cond_true)
# Entrenamiento discriminador:
# - Loss:
loss_d_real = criterion(discriminator(x_true, cond_true), ones * label_smoothing)
loss_d_fake = criterion(discriminator(x_fake.detach(), cond_true), zeros)
loss_discriminator = 1/2 * (loss_d_real + loss_d_fake)
# - Step:
discriminator_optimizer.zero_grad()
loss_discriminator.backward()
discriminator_optimizer.step()
# Entrenamiento generador (versión no saturante):
for _ in range(g_steps):
z = torch.randn(batch_size, latent_dim, device=DEVICE)
x_fake = generator(z, cond_true)
loss_generator = criterion(discriminator(x_fake, cond_true), ones)
generator_optimizer.zero_grad()
loss_generator.backward()
generator_optimizer.step()
# Log:
losses['generator'].append(loss_generator.item())
losses['discriminator'].append(loss_discriminator.item())
except KeyboardInterrupt:
print('Entrenamiento interrumpido.')
# Gráfico de entrenamiento:
plt.plot(losses['generator'], label='Generador', alpha=0.7)
plt.plot(losses['discriminator'], label='Discriminador', alpha=0.7)
plt.xlabel('Step');
plt.ylabel('Loss');
plt.legend();
plt.grid(alpha=0.3)
plt.show()Con esto, se pueden instanciar las redes neuronales y realizar el entrenamiento:
data_dim = dataset[0][0].numel()
n_classes = len(dataset.classes)
cond_embed_dim = 16
latent_dim = 64
generator = Generator(data_dim, n_classes, cond_embed_dim, latent_dim)
discriminator = Discriminator(data_dim, n_classes, cond_embed_dim)
train(generator, discriminator, latent_dim)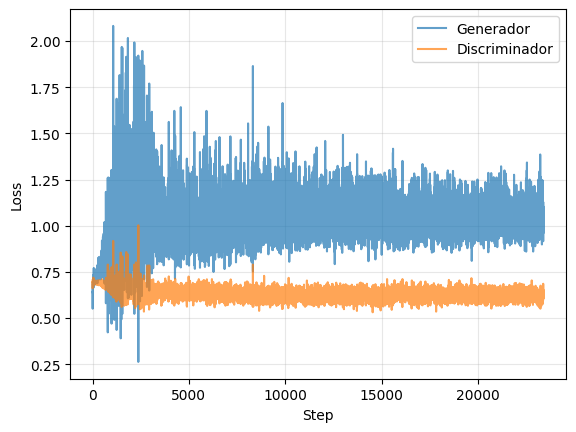
Dinámica de evolución de la CGAN.
Se observa que la dinámica de entrenamiento de la GAN es mucho más inestable e impredecible que la dinámica de, por ejemplo, los modelos autorregresivos. Más aún, la función de pérdida de ambos modelos no parece entregar ningún indicador obvio de cuándo detener el entrenamiento, o cómo detectar overfitting.
Para la generación, se utiliza la misma técnica de ancestral sampling usada en el caso incondicional, solo que además se debe incluir una condición en la red generadora:
@torch.no_grad()
def generate_samples(cond, n_samples):
generator.eval()
z = torch.randn(n_samples, latent_dim, device=DEVICE)
cond = torch.full((n_samples,), cond, dtype=torch.long, device=DEVICE)
samples = generator(z, cond)
return samples.cpu()Usando la función anterior, se generarán algunas muestras para cada etiqueta de clase:
n_samples = 15
fig, axes = plt.subplots(n_classes, n_samples, figsize=(n_samples, n_classes))
for cond in range(n_classes):
samples = generate_samples(cond=cond, n_samples=n_samples)
samples = (samples * 0.5 + 0.5).clamp(0, 1).view(len(samples), 28, 28)
for j in range(n_samples):
axes[cond, j].imshow(samples[j], cmap='gray_r')
axes[cond, j].axis('off')
axes[cond, 0].set_ylabel(str(cond), fontsize=10)
plt.tight_layout()
plt.show()
Muestras generadas por la CGAN para cada etiqueta de clase.
En la siguiente sección se estudiarán arquitecturas neuronales especializadas para imágenes, las cuales combinan distintas técnicas de diseño para inducir sesgos útiles en este tipo de datos. Como se verá, si bien las GANs tienen la capacidad de llegar a generar imágenes hiperrealistas, la principal limitación de este tipo de modelos es su inestabilidad durante el entrenamiento. Debido a esto, muchos de los trabajos en GANs consistieron principalmente en introducir modificaciones de arquitectura y heurísticas de optimización.
Redes convolucionales transpuestas
El proceso generativo de una GAN para imágenes consiste en transformar una muestra latente de baja dimensión, , en una imagen de alta dimensión, , donde para una imagen de resolución y canales. Cuando , este mapeo requiere un aumento progresivo de resolución a través de la red neuronal . Si bien esto se podría implementar con capas fully connected, este enfoque no escala bien a altas resoluciones ni aprovecha la estructura espacial de las imágenes. La operación natural que permite realizar este upsampling preservando la estructura espacial es la convolución transpuesta, también llamada convolución con stride fraccionario (o mal llamada deconvolución).
Convolución como operador lineal
Antes de estudiar las convoluciones transpuestas, se recordará el concepto de convolución1 usado en una red convolucional simple. Para esto, se considerará el caso simplificado unidimensional () con un solo canal.
Sea una entrada y un filtro convolucional de tamaño . La convolución con stride y padding produce un vector con componentes
donde y se considera para (zero-padding implícito). Se puede observar que la convolución es un operador lineal (i.e., ), por lo que existe una matriz tal que . En el caso , , esta matriz tiene estructura de Toeplitz. Por ejemplo, para , , y :
En consecuencia, una red convolucional puede verse como una red fully connected con una matriz de pesos restringida a una estructura específica, lo que reduce drásticamente el número de parámetros (de a ) y además induce sesgos útiles. En particular, dado que se comparten los pesos del kernel a lo largo de todas las posiciones espaciales de la entrada, la convolución es equivariante por traslación (si un trozo de la entrada se traslada, la salida se traslada de la misma forma). Además, cuando la convolución se combina con operaciones de pooling, la red puede volverse invariante por traslación local (la salida no cambia si se traslada localmente la entrada). Estos sesgos inductivos son especialmente útiles en visión computacional, donde se asume que los patrones relevantes (bordes, texturas, objetos) aparecen en cualquier posición de la imagen, por lo que la red no debe depender de la ubicación absoluta de estos patrones. De forma similar, este tipo de convoluciones 1D puede utilizarse para modelar el lenguaje. En este caso, el tamaño del kernel convolucional indica el tamaño de la ventana de contexto del modelo.
En el caso de más dimensión (e.g. imágenes 2D), la operación de convolución se aplica de forma independiente en cada uno de los ejes, por lo que la extensión es directa. Por otro lado, en general las convoluciones operan sobre múltiples canales de entrada (e.g. 3 canales de colores y un canal de transparencia) y producen múltiples canales de salida (cada canal un feature map). En estos casos, si la entrada tiene canales de entrada, la convolución utiliza un kernel diferente por cada canal, y las contribuciones de todos los canales se suman (elemento a elemento) para producir un único canal de salida2. De forma dual, si se necesitan canales de salida, se utiliza un bloque independiente de kernels por cada canal de salida, y las salidas se concatenan a lo largo de la dimensión de canales. En consecuencia, una capa convolucional estándar necesita aprender parámetros (más parámetros de sesgo si se consideran).
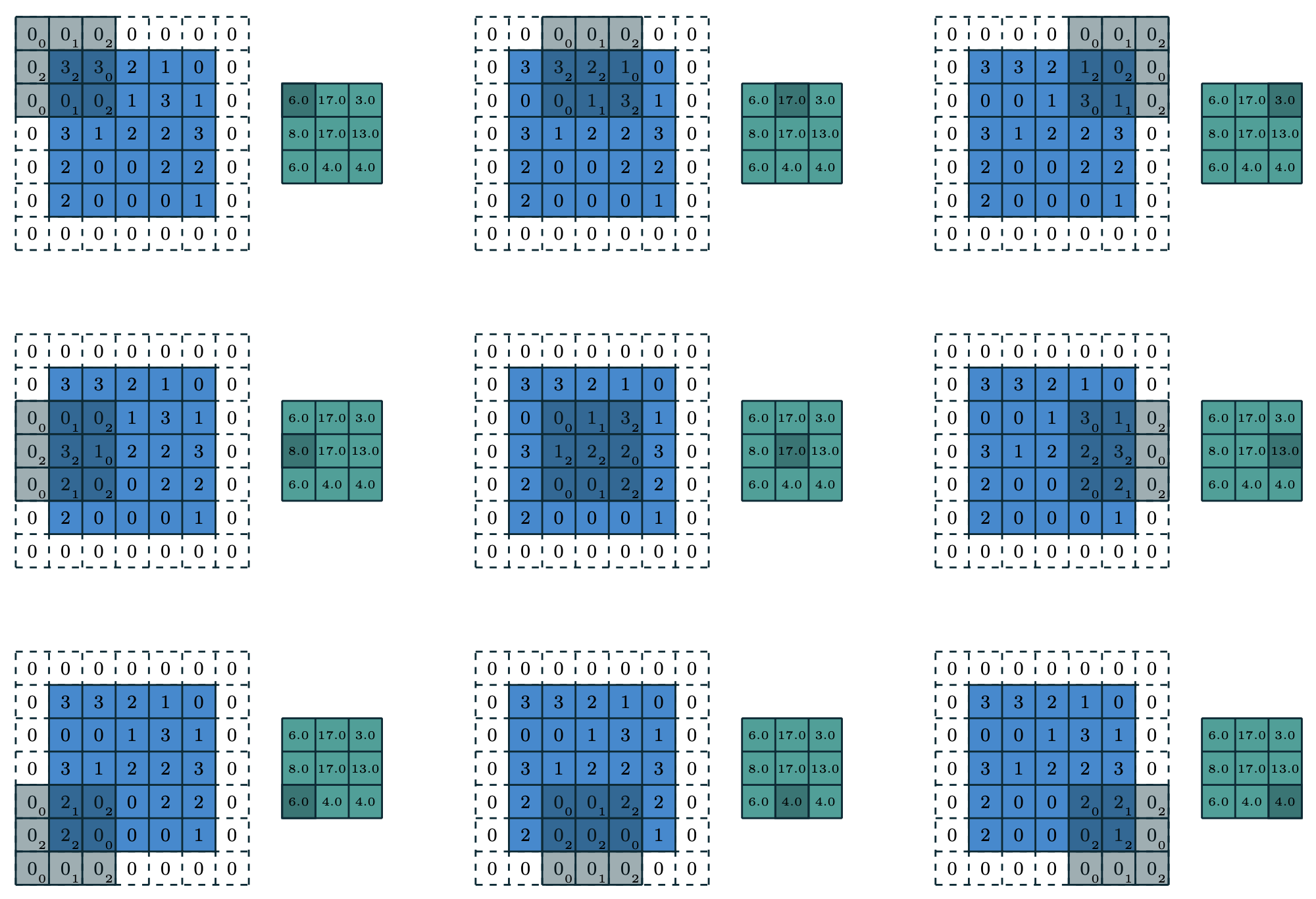
Convolución 2D con , y (mismo valor en ambas dimensiones).
Pooling
Las operaciones de pooling reducen la resolución espacial de un feature map sin cambiar el número de canales, aplicando una función de agregación sobre ventanas locales de la entrada. Las dos operaciones más comunes son max pooling (retornar el valor máximo dentro de cada ventana) y average pooling (retornar el promedio de cada ventana). Por ejemplo, para un feature map de entrada de tamaño , un max pooling con produce una salida de tamaño , donde cada posición de la salida es el máximo de una ventana de la entrada3. En arquitecturas típicas, el pooling se utiliza luego de convoluciones , las cuales no cambian la resolución (e.g., usando , ) pero sí el número de canales.
Convolución transpuesta
Dada una convolución directa con matriz asociada , la convolución transpuesta es el operador lineal (i.e., ). Considerando que en una convolución tradicional, se observa que la convolución transpuesta es un operador que permite expandir la dimensión de la entrada, al mismo tiempo que se mantienen los sesgos inductivos que caracterizan a la convolución directa. En particular, este tipo de operador permite realizar un aumento de la resolución a medida que se avanza en una red neuronal generadora (como en una GAN o en un VAE).
Interpretando la convolución directa como un mecanismo que agrega información de la entrada (cada elemento de la salida recibe contribuciones de elementos de la entrada), la convolución transpuesta puede interpretarse como un mecanismo que distribuye el valor de cada elemento de la entrada sobre posiciones de la salida. Más aún, se puede ver que la convolución transpuesta con stride es operacionalmente equivalente a insertar ceros entre cada par de elementos consecutivos de la entrada y luego aplicar una convolución directa con stride y padding . Esta interpretación explica el nombre stride fraccionario (el filtro avanza efectivamente posiciones por cada elemento del input original).
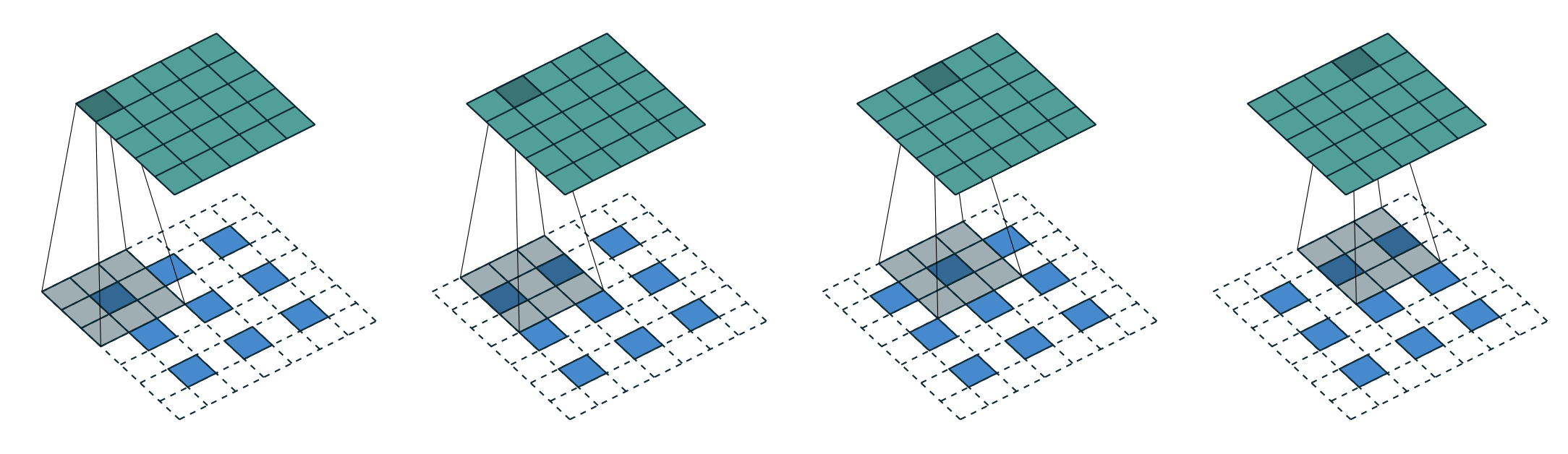
Convolución transpuesta 2D vista como una convolución con stride fraccionario.
Por otra parte, despejando desde (asumiendo división exacta), es posible obtener la dimensión de salida que produce una convolución transpuesta con kernel de tamaño , stride y padding sobre una entrada de largo :
En arquitecturas generativas las convolución con , , y la convolución con , , duplican la resolución espacial (i.e., ), por lo que son convoluciones transpuestas usuales en redes neuronales generativas.
Artefactos de tablero
Cuando no es múltiplo de , el filtro se superpone de forma desigual sobre la salida, lo que provoca que algunas posiciones reciban contribuciones de elementos de la entrada, mientras que otras reciben contribuciones de elementos.
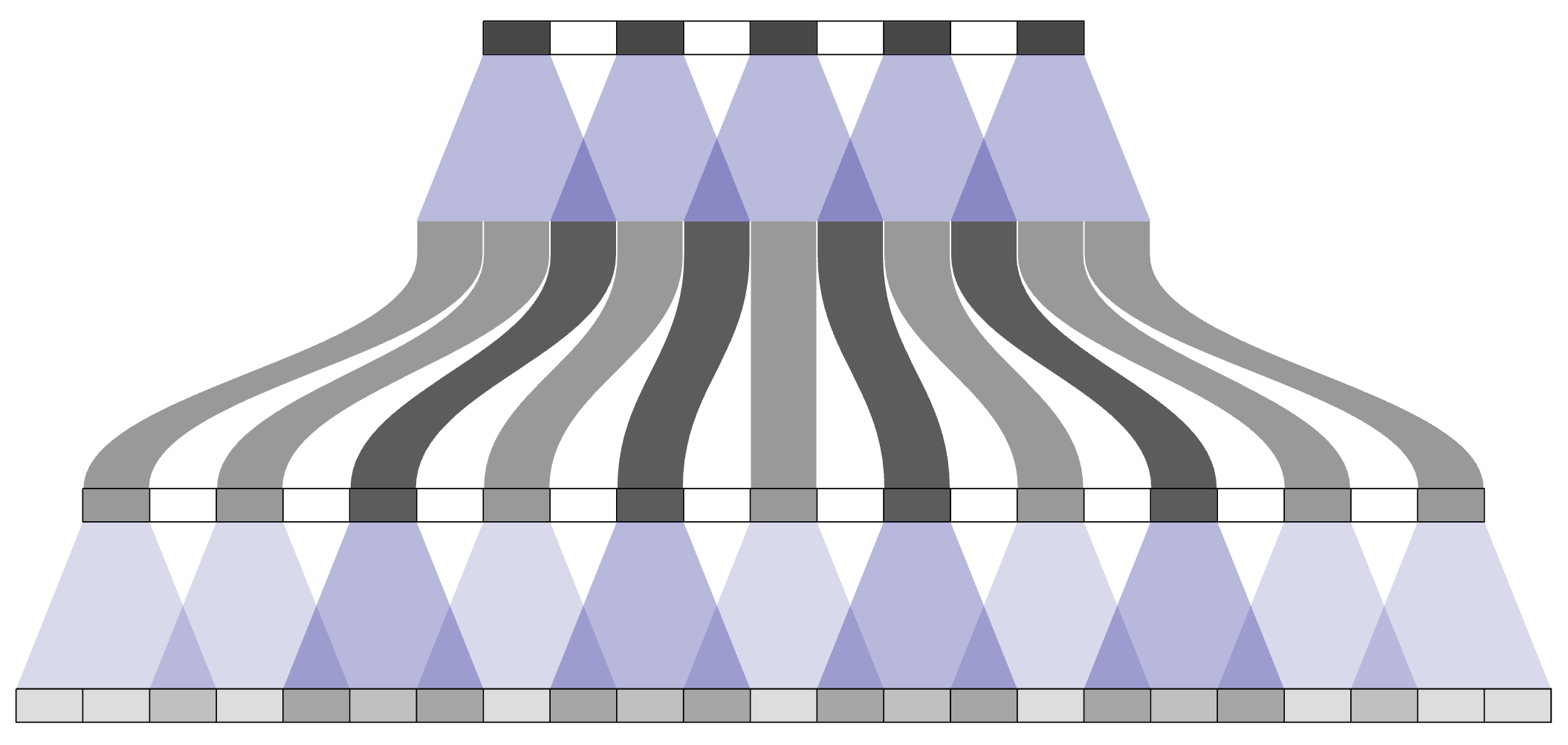
Periodicidad en la cantidad de contribuyentes para cada posición de salida.
Esta periodicidad se manifiesta como un patrón visual de cuadrícula en la imagen generada, conocido como checkerboard artifact.

Ejemplos de checkboard artifacts en distintas imágenes generadas.
Existen dos estrategias usuales para evitar estos artefactos:
Elegir múltiplo de (típicamente ), de modo que todas las posiciones reciban el mismo número de contribuyentes.
Reemplazar la convolución transpuesta por una interpolación explícita (e.g., bilineal o nearest neighbor) para aumentar la resolución, seguida de una convolución que cambie la cantidad de canales pero no la resolución (e.g., , , ).
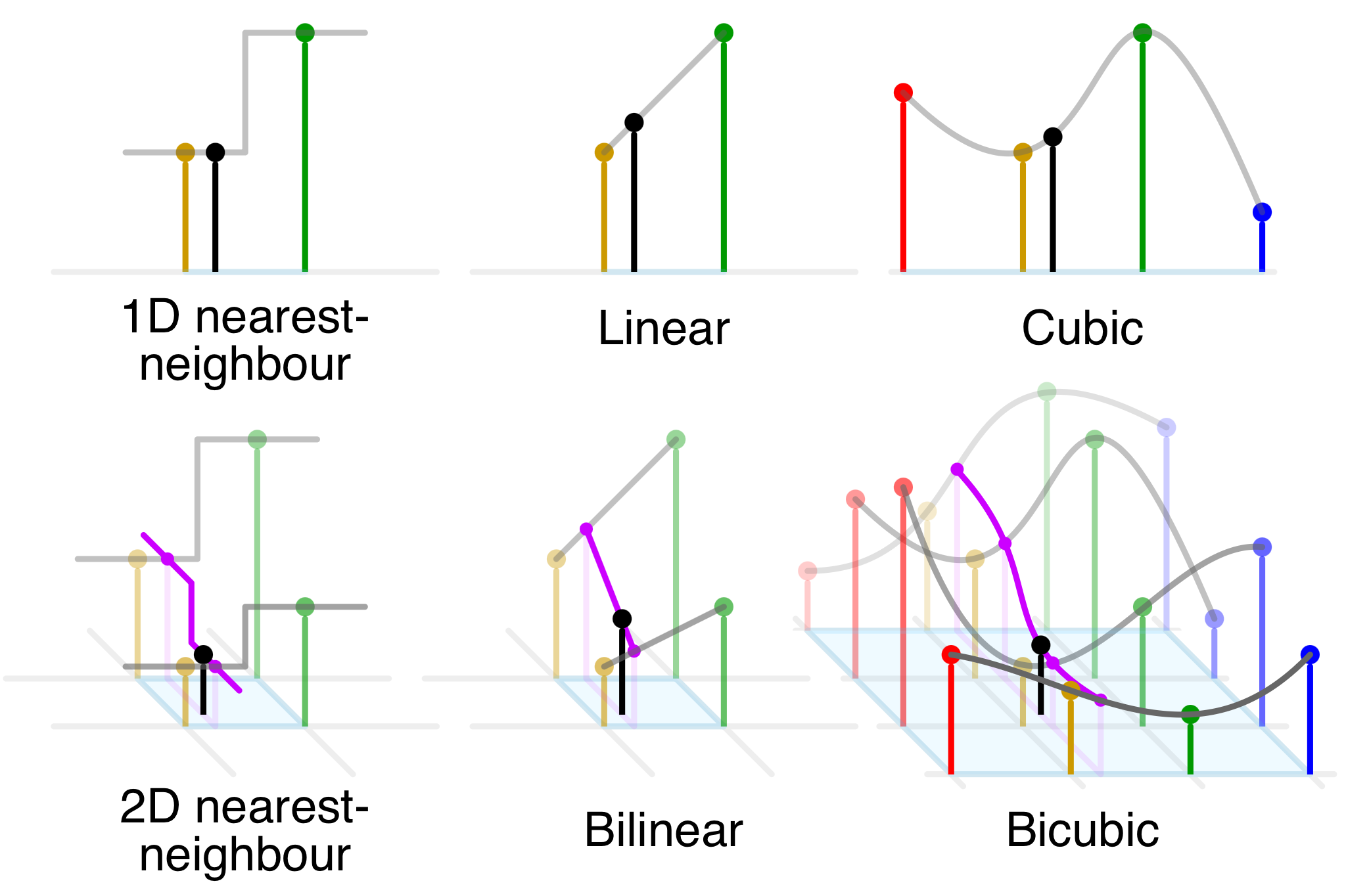
Comparación de interpolaciones en los casos y .
Algunas GANs famosas
Las GANs constituyeron el estado del arte para la generación de imágenes entre los años y , hasta la consolidación de los modelos de difusión. Como se mencionó, una parte importante de los trabajos sobre GANs estuvo enfocada en desarrollar mejores arquitecturas neuronales, con el objetivo de mitigar las inestabilidades del entrenamiento y propagar la información condicional de forma efectiva. Otra línea de investigación se dedicó a modificar la función de entrenamiento original, proponiendo formulaciones más estables o ligadas a divergencias con mejores propiedades geométricas (algunas divergencias serán estudiadas en el siguiente capítulo). Una tercera línea estuvo enfocada en obtener resultados teóricos sobre las GANs, como propiedades de convergencia y conexiones con teoría de juegos.
El siguiente diagrama muestra un orden temporal de los modelos tipo GAN más relevantes, junto con otros desarrollos contemporáneos como contexto histórico:
En esta sección se revisarán algunas arquitecturas y modelos tipo GAN que se consideran relevantes en el campo. Si bien hay muchos otros trabajos importantes, la elección de estos modelos es principalmente debido a que algunas de sus propuestas fueron hereadadas a arquitecturas más modernas usadas en modelos de difusión (e.g. el uso de la U-Net con módulos de atención). Si bien no se seguirá el orden cronológico, cada arquitectura se motivará como respuesta a una limitación concreta de la anterior. En particular, DCGAN partirá dando reglas básicas para estabilizar el entrenamiento de GANs convolucionales, SAGAN incorporará dependencias globales para mejorar la coherencia geométrica, ProGAN permitirá escalar a mayores resoluciones mediante un entrenamiento progresivo, y StyleGAN reorganizará el generador para desacoplar factores de variación de alto y bajo nivel.
Deep convolutional GAN
La GAN original utilizaba redes fully connected, las cuales no aprovechan la estructura espacial de las imágenes y no escalan a resoluciones altas. Deep convolutional GAN (DCGAN) [8] reemplaza estas redes por arquitecturas convolucionales profundas y propone, mediante una extensa exploración empírica, un conjunto de restricciones arquitectónicas que estabilizan el entrenamiento. La contribución central de este trabajo es haber definido reglas generales para el diseño de arquitecturas para GANs. Adicionalmente, DCGAN mostró que tanto el generador como el discriminador aprenden representaciones semánticamente estructuradas, lo cual es destacable considerando que el entrenamiento es, al igual que en los modelos de lenguaje, autosupervisado (las etiquetas se obtienen automáticamente).
Restricciones arquitectónicas
Una técnica ampliamente utiliza en GANs es batch normalization (BN) [9]. Este módulo normaliza las pre-activaciones de cada neurona a media nula y varianza unitaria, y luego les aplica una transformación afín con parámetros aprendibles , con cada par de parámetros aprendido de forma independiente para cada canal.
Si es un batch de imágenes4, durante el entrenamiento BN devuelve un tensor del mismo tamaño definido componente a componente por
DCGAN propone construir una GAN para imágenes utilizando redes convolucionales con las siguientes cinco restricciones:
Batch normalization en y : se debe aplicar BN a todas las capas intermedias de y , excepto en la salida de (cuya distribución de píxeles no debe ser forzada a ser gaussiana) y en la entrada de (donde mezclar estadísticas de muestras reales y sintéticas en la primera capa degrada el clasificador).
Sustitución de pooling por convoluciones con stride: el downsampling en se debe realizar mediante convoluciones con en vez de usar max-pooling, mientras que el upsampling en se debe realizar mediante convoluciones transpuestas con . En ambos casos, estos cambios le permite a la red aprender sus propias funciones de muestreo (kernels) en lugar de usar operadores fijos.
Eliminación de capas fully connected ocultas: en las primeras GANs, tanto como eran redes fully connected que trataban la imagen como un vector plano. En DCGAN el código latente se proyecta linealmente a un tensor en mediante una única capa lineal seguida de un reshape, y el resto de la arquitectura opera exclusivamente con convoluciones.
Activaciones en : en el generador, todas las capas ocultas deben usar , excepto la capa de salida que debe usar , cuyo rango es simétrico alrededor de cero6. Se prefiere sobre la sigmoide estándar debido a que tiene gradientes más fuertes cerca de los valores extremos, lo que facilita el aprendizaje de píxeles con intensidades altas o bajas. Además, el rango simétrico es más natural para representar imágenes normalizadas que el rango asimétrico de la sigmoide.
Activaciones en : en el discriminador, todas las capas deben usar en lugar de ( con ). Esta elección garantiza gradientes no nulos en todo , lo que es crítico al inicio del entrenamiento, cuando produce imágenes de muy mala calidad.
Hiperparámetros de Adam
El algoritmo de optimización Adam [5] mantiene dos estimaciones acumuladas para cada parámetro , las cuales corresponden al primer y segundo momento de los gradientes. Estas estimaciones se actualizan en cada step de entrenamiento mediante
donde es el gradiente en el paso y el cuadrado en se realiza coordenada a coordenada. El parámetro controla cuánta memoria mantiene Adam de la dirección media de los gradientes pasados (mayor implica más momentum), mientras que controla la memoria para estimar la varianza. Tras aplicar corrección de sesgo, y , la actualización de parámetros que realiza Adam es
con las operaciones de raíz y división aplicada coordenada a coordenada. Notar que la corrección de sesgo es necesaria ya que, al inicio del entrenamiento ( pequeño), las estimaciones y están sesgadas hacia cero (ya que se inicializan en cero y los factores son cercanos a ). Dividir por cancela este sesgo, ya que cuando . La división normaliza cada componente del gradiente por su desviación estándar histórica, implementando una tasa de aprendizaje adaptativa por parámetro que acelera la convergencia en direcciones con gradientes consistentes, y frena el aprendizaje en direcciones ruidosas.
Si bien los valores por defecto de Adam son , DCGAN propone utilizar . Durante el entrenamiento de una GAN, las redes neuronales y son adaptadas de manera adversativa, por lo que los gradientes del generador suelen cambiar de signo con frecuencia (ya que una dirección favorable en el paso puede volverse perjudicial para en el paso si el discriminador ha cambiado). Con , Adam promedia gradientes a lo largo de aproximadamente pasos7 (ya que ), por lo que, en una GAN, la actualización estándar de Adam muchas veces seguiría direcciones obsoletas, produciendo oscilaciones. DCGAN reduce a ya que esta elección acorta la memoria efectiva a aproximadamente pasos, haciendo a Adam más reactivo a la información reciente de los gradientes.
Propiedades emergentes del espacio latente
El trabajo de DCGAN mostró que las representaciones aprendidas por una GAN, aun en un escenario autosupervisado, capturan propiedades semánticas no triviales. En particular, al utilizar las activaciones convolucionales intermedias del discriminador como entrada para un clasificador lineal entrenado sobre CIFAR-10 y SVHN, DCGAN logró obtener resultados competitivos respecto a métodos clásicos de aprendizaje no supervisado.
Más aún, en DCGAN observaron que el espacio latente exhibe una estructura algebraica con efectos semánticos. Más precisamente, si son dos muestras del prior , la curva de imágenes dada por , , corresponde a una interpolación semántica entre las imágenes y , en la cual los atributos relevantes de la imagen varían suavemente.

Interpolación latente en DCGAN. Imagen obtenida desde [8].
En particular, esta propiedad del espacio latente de una GAN permite realizar aritmética vectorial en el espacio latente con efectos semánticos interpretables, de forma similar a como se pueden operar los vectores de embedding de un vocabulario de texto. Por ejemplo, si , y son promedios de vectores latentes que generan imágenes con los atributos correspondientes, entonces el vector latente
(y una vecindad suya) genera imágenes de mujeres con lentes, sugiriendo que aprende representaciones con cierto grado de linealidad semántica.
Este tipo de modificación de atributos será implementado al estudiar VAEs, donde además se verá como aumentar y disminuir la intensidad del atributo a modificar.

Aritmética vectorial en el espacio latente de DCGAN. Imagen obtenida desde [8].
Self-attention GAN
Si bien DCGAN produce resultados notables a , a mayor resolución presenta varias limitaciones que motivan las siguientes arquitecturas. En particular, las arquitecturas convolucionales clásicas presentan dificultades al modelar patrones con estructura geométrica compleja, donde las partes de un objeto deben mantener coherencia global (e.g., imágenes de animales). Esta limitación surge porque las convoluciones procesan información de manera local, restringiendo el modelado de dependencias de largo alcance y, si bien apilar varias capas convolucionales expande el campo receptivo, esto incrementa significativamente la profundidad y el costo computacional.
Self-attention GAN (SAGAN) [10] introduce un módulo de self-attention que captura dependencias entre cualquier par de posiciones del feature map con un único bloque, generando imágenes a en la tarea de generación condicional (por clase) sobre ImageNet.
Módulo de self-attention
Para tratar un feature map convolucional como una secuencia, se puede considerar cada pixel como un token, donde la dimensión de embedding del token correspondería a la cantidad de canales. Si son los vectores asociados a las posiciones espaciales (con canales), el módulo de self-attention en SAGAN parte realizando tres proyecciones lineales implementadas como convoluciones :
donde son matrices de parámetros y es la dimensión del cabezal. La similitud entre las posiciones y se calcula mediante el producto interno , y los pesos de atención se obtienen aplicando softmax por filas sobre la matriz de scores:
Luego vector de salida en la posición agrega los valores ponderados y aplica una proyección de salida al único cabezal de atención para volver a la dimensión original:
Finalmente, la salida se inyecta como una conexión residual con compuerta:
El parámetro de compuerta, , es un escalar aprendible inicializado en cero. Con , la salida del módulo de atención es , por lo que la red se reduce a su contraparte puramente convolucional al inicio del entrenamiento. A medida que crece durante la optimización, el módulo incorpora información de largo alcance de forma gradual, evitando perturbaciones no locales que desestabilizarían el entrenamiento en las iteraciones iniciales.
Observación 1. A diferencia de la scaled dot-product attention de [11], SAGAN no divide los logits por (el control de magnitudes se delega a la normalización espectral8), y tampoco se usa layer normalization dentro del módulo.
Para elegir donde colocar los mecanismos de atención, notar que en resoluciones menores, el campo receptivo de la convolución ya cubre prácticamente todo el feature map, mientras que en resoluciones mayores el costo cuadrático de la atención se vuelve prohibitivo. Por este motivo, los autores de SAGAN sugieren insertar el módulo en el feature map de ya que esta resolución ofrece la mejor relación costo-beneficio.

Visualización de los mapas de atención en SAGAN. Imagen obtenida desde [10].
Empíricamente, incorporar un mecanismo atención produce un aumento sustancial en la calidad de las imágenes generadas, especialmente en clases con patrones geométricos complejos. Debido a esto, el mecanismo de atención introducido por SAGAN ha influido notablemente en arquitecturas posteriores, como la U-Net usadas en modelos de difusión, donde se combinan bloques convolucionales con bloques de self-attention en las resoluciones intermedias siguiendo la idea de SAGAN.
Hinge aversarial loss
En la formulación estándar de una GAN, el discriminador produce una probabilidad y se entrena siguiendo el enfoque de máxima verosimilitud. En SAGAN, produce un puntaje real sin restricción a , y se entrena con la hinge adversarial loss:
Para muestras reales, el objetivo es , y la penalización solo se activa cuando . Para muestras sintéticas, el objetivo es , y la penalización solo se activa cuando . Notar que esta función de pérdida es análoga a la pérdida de margen de las SVMs, y evita que siga sobre-entrenando en ejemplos fáciles, lo que reduce la saturación de los gradientes que recibe .
Progressive GAN
SAGAN mejora la coherencia global de las muestras pero sigue limitado a , ya que el costo cuadrático de la atención y la dificultad de optimizar redes profundas a alta resolución impiden escalar la arquitectura directamente. ProGAN [12] fue el primer método en producir imágenes realistas a resolución . La idea central es un curriculum learning9 explícito, donde en lugar de entrenar los modelos directamente en la resolución final, y comienzan con arquitecturas simétricas que operan en resolución baja () y se van agregando pares de capas de manera progresiva hasta alcanzar la resolución objetivo.
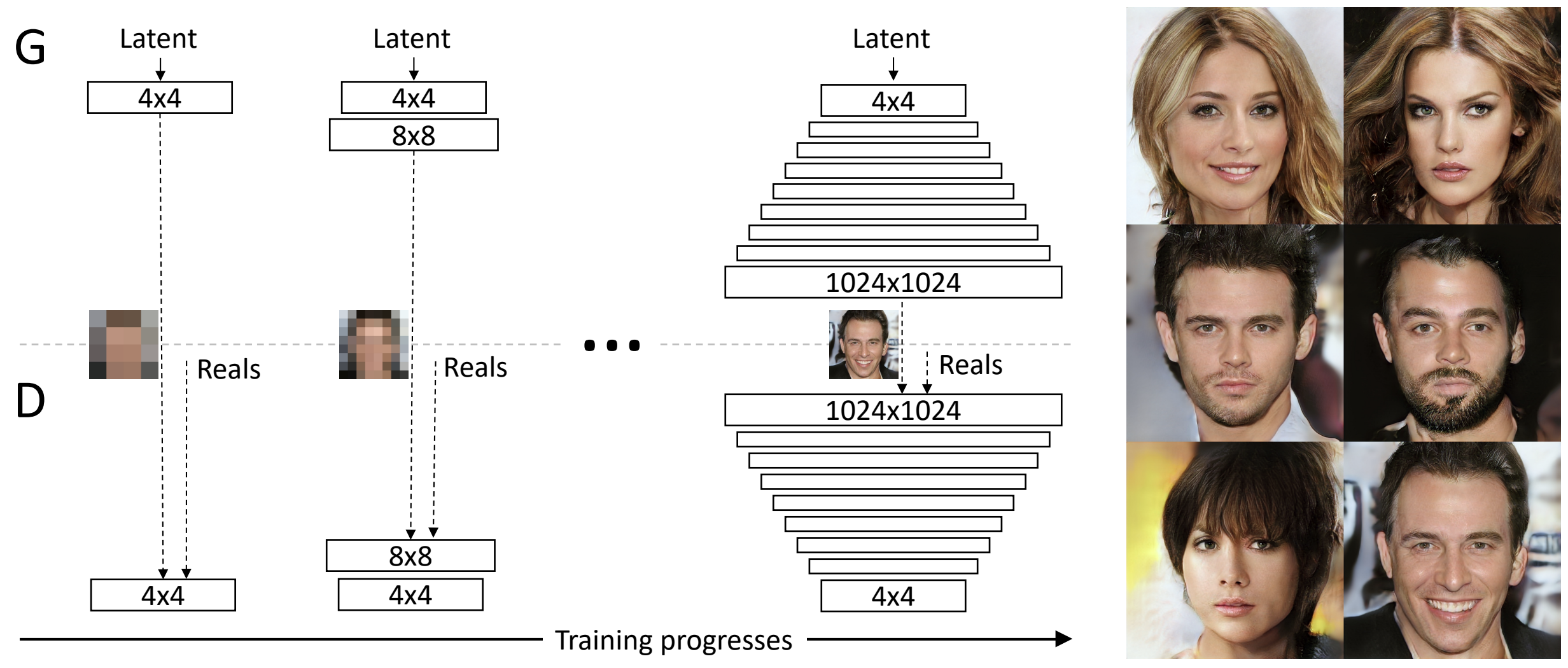
Arquitectura de ProGAN (izquierda) e imágenes generadas por el modelo (derecha).
Entrenamiento progresivo
Sean y las versiones de y a resolución . Al pasar de la resolución a , ProGAN agrega un bloque convolucional en la parte superior de para realizar el upsampling y, simétricamente, un bloque en la parte inferior de para realizar el downsampling . Las imágenes reales de entrenamiento se redimensionan a la resolución actual y las nuevas capas se incorporan mediante un mecanismo de fade-in (explicado más abajo). Además, todas las capas existentes se siguen considerando entrenables al agregar las nuevas capas (esto permite interpretar el entrenamiento previo como una buena inicialización). Como resultado, los autores de ProGAN encontraron que, a igual presupuesto de cómputo, el entrenamiento progresivo es significativamente más rápido y estable que entrenar directamente en alta resolución.
Para cada nueva resolución , al generador se le agrega una capa al final, mientras que al discriminador se le agrega una capa al inicio. Estas capas cumplen la función de mapear entre el espacio de imágenes RGB y el espacio de features convolucionales, y viceversa. Ambas funciones son implementadas como convoluciones que cambian la cantidad de canales sin alterar la resolución espacial.
Con respecto a la función objetivo, ProGAN es entrenado utilizando la pérdida WGAN-GP (estudiada en el próximo capítulo). También se utilizan otras heurísticas de entrenamiento y arquitectura, pero no se mencionarán ya que no son tan relevantes.
Fade-in de nuevas capas
Introducir nuevas capas de golpe altera considerablemente la función aprendida, lo que desestabiliza el entrenamiento. Para evitarlo, ProGAN utiliza una interpolación lineal controlada por un parámetro que crece de a a lo largo de steps de actualización. Más precisamente, durante la transición , la salida del generador es:
donde es el último feature map de a resolución , es una interpolación determinista (e.g. nearest neighbor o bicúbica) y es la nueva convolución que opera en resolución . Simétricamente, durante la transición , el discriminador se actualiza de la siguiente forma:
donde es la imagen real a resolución , es average pooling y es el nuevo bloque convolucional que pasa de resolución a . En se recuperan las arquitecturas de la resolución anterior y en las nuevas capas están completamente activas.
StyleGAN
Pendiente.
Arquitectura U-Net
Si bien las arquitecturas anteriores permiten generar imágenes en alta resolución, no es claro cómo utilizarlas de manera condicional cuando la condición es una imagen (e.g., en tareas image-to-image). La arquitectura U-Net [13] es una red completamente convolucional con forma de autoencoder10 que incluye skip connections entre los bloques del encoder y los bloques homólogos en el decoder. Por otro lado, si bien esta arquitectura fue propuesta originalmente para la tarea de segmentación semántica (donde cada píxel de una imagen se clasifica individualmente), esta arquitectura es de gran importancia tanto en GANs como en modelos de difusión, donde la arquitectura debe recibir versiones más ruidosas de la imagen a generar, por lo que naturalmente se necesita una arquitectura tipo image-to-image.
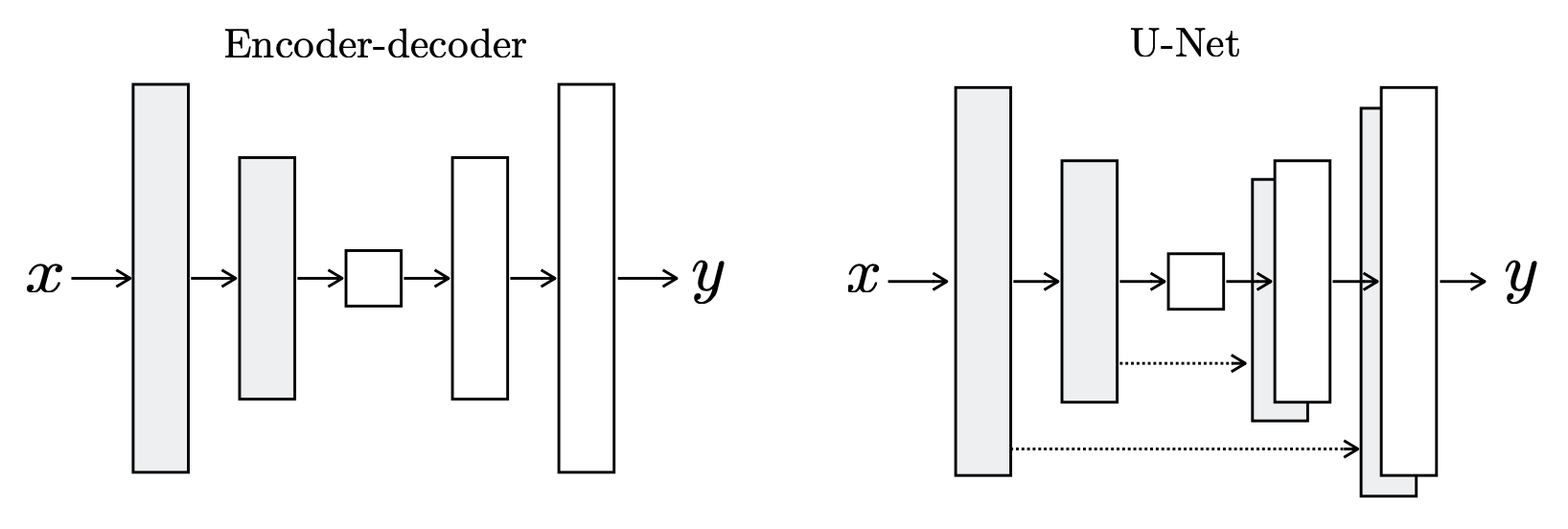
Comparación entre un autoencoder (izquierda) y la arquitectura U-Net (derecha). Imagen obtenida desde [14].
Por otro lado, hoy en día los modelos generativos de imágenes suelen utilizar arquitecturas tipo ViT (e.g. Diffusion Transformer), donde una imagen se patchifica para poder tratarla como una secuencia de tokens usando un Transformer.
El siguiente diagrama muestra una U-Net con dos bloques de bajada y dos bloques de subida. En cada bloque, la tupla superior indica la resolución de entrada y la tupla inferior indica la resolución de salida del bloque:
(H, W, C)"] --> Phi0["Convolución
(H, W, C)
(H, W, 64)"] Phi0 --> Down0["Downsample
(H, W, 64)
(H/2, W/2, 64)"] Down0 --> Phi1["Convolución
(H/2, W/2, 64)
(H/2, W/2, 128)"] Phi1 --> Down1["Downsample
(H/2, W/2, 128)
(H/4, W/4, 128)"] Down1 --> Phi2["Convolución
(H/4, W/4, 128)
(H/4, W/4, 256)"] Phi2 --> Up1["Upsample
(H/4, W/4, 256)
(H/2, W/2, 128)"] Up1 --> Psi1["Concat + Conv
(H/2, W/2, 256)
(H/2, W/2, 128)"] Psi1 --> Up0["Upsample
(H/2, W/2, 128)
(H, W, 64)"] Up0 --> Psi0["Concat + Conv
(H, W, 128)
(H, W, 64)"] Psi0 --> Out["Conv1×1
(H, W, 64)
(H, W, C)"] Phi0 -.- Psi0 Phi1 -.- Psi1 subgraph Encoder Phi0 Down0 Phi1 Down1 end subgraph Middle Phi2 end subgraph Decoder Up1 Psi1 Up0 Psi0 end classDef default fill:#f9f9f9,stroke:#333,stroke-width:2px; classDef encoder fill:#fce4ec,stroke:#333,stroke-width:2px; classDef middle fill:#e3f2fd,stroke:#333,stroke-width:2px; classDef decoder fill:#fff8e1,stroke:#333,stroke-width:2px; class Phi0,Down0,Phi1,Down1 encoder; class Phi2 middle; class Up1,Psi1,Up0,Psi0 decoder; class Input,Out default;
Cada bloque de bajada del encoder se conecta a su bloque de subida homólogo en el decoder mediante una skip connection (concatenación en la dimensión de los canales). Esto facilita la transmisión directa de información de bajo nivel desde el encoder hacia el decoder, ayudando al modelo a conservar detalles espaciales finos. Las modificaciones modernas de esta arquitectura suelen incorporar bloques de self-attention en algunas resoluciones (similar a SAGAN) y mecanismos de atención cruzada para condicionamiento textual, lo cual será revisado al estudiar modelos de difusión.
Implementación
Dada la importancia de esta arquitectura neuronal para los modelos generativos, se entregará una implementación minimal de una U-Net, y luego se utilizará esta implementación para entrenar un modelo de segmentación semántica sobre el dataset Oxford-IIIT Pet. Para simplificar la implementación, no se incluirán bloques de normalización ni dropout u otro tipo de regularizaciones. En el próximo capítulo se adaptará esta arquitectura para ser utiliza en modelo Pix2Pix (GAN para traducción de imágenes), y luego se adaptará con bloques de self-attention al implementar un modelo de difusión para imágenes.
La U-Net es una arquitectura completamente convolucional, por lo que se comenzará definiendo un módulo ConvBlock, formado por dos convoluciones con (i.e., no cambia la resolución). En caso de querer cambiar la cantidad de canales, esto se hará en la primera convolución11.
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
)
def forward(self, x):
return self.conv(x)Cada bloque de bajada del encoder, implementado en DownBlock, está compuesto por una ConvBlock (que duplica los canales sin cambiar la resolución) seguida de una operación de pooling (que divide en dos la resolución sin cambiar los canales). En consecuencia, cada DownBlock duplica la cantidad de canales y reduce la resolución a la mitad. Este bloque retorna, además, la salida de la convolución (antes del pooling) para que sea usada en la skip connection con el decoder en la resolución homóloga respectiva.
class DownBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = ConvBlock(in_channels, out_channels)
self.down = nn.MaxPool2d(kernel_size=2)
def forward(self, x):
skip = self.conv(x)
return self.down(skip), skipPor otro lado, cada bloque de subida del decoder, implementado en UpBlock, parte duplicando la resolución y dividiendo los canales por dos usando una convolución transpuesta12. Luego, realiza la skip conection, concatenando lo anterior con el bloque auxiliar homólogo del encoder. Finalmente, se aplica una ConvBlock para ajustar a la cantidad de canales de salida deseada. En consecuencia, cada UpBlock reduce a la mitad la cantidad de canales y duplica la resolución.
class UpBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = ConvBlock(in_channels, out_channels)
def forward(self, x, skip):
x = self.up(x)
x = torch.cat([x, skip], dim=1)
return self.conv(x)Con estos bloques, la U-Net completa se construye de forma simétrica. Los bloques del decoder reciben las skip connections del encoder en orden inverso, y la salida del último bloque del decoder pasa por una convolución para ajustar la cantidad de canales a la salida deseada (n_classes en la tarea de segmentación semántica, o 3 en la tarea de generación de imágenes).
class UNet(nn.Module):
def __init__(self, in_channels, n_classes, base_ch=64):
super().__init__()
self.down1 = DownBlock(in_channels, base_ch)
self.down2 = DownBlock(base_ch, base_ch * 2)
self.down3 = DownBlock(base_ch * 2, base_ch * 4)
self.down4 = DownBlock(base_ch * 4, base_ch * 8)
self.bottleneck = ConvBlock(base_ch * 8, base_ch * 16)
self.up4 = UpBlock(base_ch * 16, base_ch * 8)
self.up3 = UpBlock(base_ch * 8, base_ch * 4)
self.up2 = UpBlock(base_ch * 4, base_ch * 2)
self.up1 = UpBlock(base_ch * 2, base_ch)
self.out = nn.Conv2d(base_ch, n_classes, kernel_size=1)
def forward(self, x):
x, skip1 = self.down1(x)
x, skip2 = self.down2(x)
x, skip3 = self.down3(x)
x, skip4 = self.down4(x)
x = self.bottleneck(x)
x = self.up4(x, skip4)
x = self.up3(x, skip3)
x = self.up2(x, skip2)
x = self.up1(x, skip1)
return self.out(x)Aplicación a segmentación semántica
Si bien esta arquitectura será utilizada en modelos generativos, U-Net fue propuesta originalmente para la tarea de segmentación semántica en imágenes médicas, donde se busca clasificar individualmente cada pixel de una imagen para construir un mapa de segmentación (máscara) y poder identificar diferentes estructuras o regiones de interés. Aquí se entrenará el modelo anterior sobre el dataset Oxford-IIIT Pet, el cual contiene imágenes de mascotas junto a sus mapas de segmentación (fondo, mascota y borde).
Para comenzar, todas las imágenes y máscaras se redimensionarán a resolución . Notar que las máscaras se deben interpolar utilizando métodos como InterpolationMode.NEAREST para evitar valores intermedios que no corresponderían a etiquetas válidas (fuera de ):
img_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
])
mask_transform = transforms.Compose([
transforms.Resize((256, 256), interpolation=transforms.InterpolationMode.NEAREST),
transforms.PILToTensor(),
])
def transform(img, mask):
img = img_transform(img)
mask = mask_transform(mask).long().squeeze()
return img, (mask - 1)
dataset = datasets.OxfordIIITPet(
root='data', download=True, target_types='segmentation', transforms=transform,
)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, drop_last=True)
Ejemplo de imagen y máscara de segmentación del dataset Oxford-IIIT Pet.
Para entrenar el modelo se seguirá el enfoque de máxima verosimilitud del clasificador minimizando la entropía cruzada, aplicada a nivel de pixel, donde la función de pérdida total es el promedio sobre todos los píxeles de las pérdidas individuales.
def train(model, optimizer, dataloader, n_epochs):
model.to(DEVICE)
model.train()
loss_fn = nn.CrossEntropyLoss()
losses = []
try:
for epoch in range(n_epochs):
pbar = tqdm(dataloader, desc=f'Época {epoch+1}/{n_epochs}')
for imgs, masks in pbar:
imgs, masks = imgs.to(DEVICE), masks.to(DEVICE)
logits = model(imgs)
loss = loss_fn(logits, masks)
optimizer.zero_grad()
loss.backward()
optimizer.step()
pbar.set_postfix(loss=loss.item())
losses.append(loss.item())
except KeyboardInterrupt:
print('Entrenamiento interrumpido.')
training_log = {'model': model.state_dict(), 'losses': losses}
torch.save(training_log, 'training.pt')Finalmente, se entrenará el modelo y se graficará su dinámica de entrenamiento.
# Entrenamiento:
model = UNet(in_channels=3, n_classes=3)
optimizer = optim.Adam(model.parameters(), lr=1e-4)
train(model, optimizer, dataloader, n_epochs=50)
# Carga del modelo entrenado:
training_log = torch.load('training.pt', map_location=DEVICE, weights_only=True)
model.load_state_dict(training_log['model'])
Curva de pérdida durante el entrenamiento de la U-Net para la tarea de segmentación.
Una vez entrenado el modelo, la predicción de la máscara para una imagen dada se obtiene aplicando sobre los logits de salida en la dimensión de las clases.
def predict_mask(model, img):
model.eval()
with torch.no_grad():
img = img.unsqueeze(0).to(DEVICE)
logits = model(img)
probs = torch.softmax(logits, dim=1)
pred_mask = torch.argmax(probs, dim=1)
return pred_mask.squeeze().cpu()
Imagen original, máscara real y predicción del modelo entrenado.
Más correctamente, esta operación corresponde a la correlación cruzada, ya que la convolución contiene el índice desfasado e invertido. En la práctica ambos conceptos son equivalentes a nivel de capacidad de aprendizaje, y el nombre de convolución es el más usual en deep learning.↩︎
Equivalentemente, se puede considerar un único kernel -dimensional que convolucione con los canales de entrada.↩︎
En particular, max pooling puede considerarse como un detector de características que se activa cuando al menos un elemento del campo receptivo posee la feature buscada (invarianza local).↩︎
En general, un objeto tipo imagen es un tensor 3D formado por un conjunto de mapas de características 2D, donde cada mapa de características corresponde a un canal de la imagen. En particular, se le dirá imagen a la entrada y salida de cualquier bloque convolucional 2D.↩︎
Tras cada batch de entrenamiento se actualiza , donde es un hiperparámetro de momentum. De forma análoga se actualiza .↩︎
Las imágenes de entrenamiento se deben normalizar al mismo rango.↩︎
La cantidad de pasos de memoria efectiva de una media móvil exponencial (EMA) con parámetro se puede estimar como . Esto proviene de observar que en la actualización , el peso del gradiente en el paso es proporcional a , que decae exponencialmente. Luego, la suma acumulada de pesos, , entrega una medida del horizonte temporal efectivo de la EMA.↩︎
Dada una capa lineal con matriz de pesos , la normalización espectral reemplaza por , donde es el mayor valor singular de , el cual puede ser estimado eficientemente.↩︎
Esto es, un enfoque de aprendizaje progresivo donde la red se entrena primero en tareas más simples y luego se incrementa la dificultad.↩︎
Es decir, una red neuronal que primero comprime la información y luego la reconstruye. Estas redes serán estudiadas en más profundidad en el capítulo de autoencoders variacionales.↩︎
Esto es una decisión de diseño. De forma relacionada, el paper original de U-Net no incluye padding, por lo que las resoluciones van disminuyendo levemente. Aquí se seguirá la elección natural de usar .↩︎
Esto se realiza para que, al concatenar con la skip connection del encoder (el cual tiene la misma resolución), la cantidad de canales coincida.↩︎
Referencias
- Goodfellow, Ian J., Pouget-Abadie, Jean, Mirza, Mehdi, Xu, Bing, Warde-Farley, David, Ozair, Sherjil, Courville, Aaron, Bengio, Yoshua, “Generative Adversarial Nets”, Advances in Neural Information Processing Systems (NeurIPS), 2014. https://arxiv.org/abs/1406.2661
- Mohamed, Shakir, Lakshminarayanan, Balaji, “Learning in Implicit Generative Models”, arXiv preprint arXiv:1610.03483, 2016. https://arxiv.org/abs/1610.03483
- Google Developers, “Overview of GAN Structure”, Machine Learning Crash Course, 2022. https://developers.google.com/machine-learning/gan/gan_structure
- scikit-learn developers, “sklearn.datasets.make\_swiss\_roll”. https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_swiss_roll.html
- Kingma, Diederik P., Ba, Jimmy, “Adam: A Method for Stochastic Optimization”, International Conference on Learning Representations (ICLR), 2015. https://arxiv.org/abs/1412.6980
- Mirza, Mehdi, Osindero, Simon, “Conditional Generative Adversarial Nets”, arXiv preprint arXiv:1411.1784, 2014. https://arxiv.org/abs/1411.1784
- Rombach, Robin, Blattmann, Andreas, Lorenz, Dominik, Esser, Patrick, Ommer, Björn, “High-Resolution Image Synthesis with Latent Diffusion Models”, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. https://arxiv.org/abs/2112.10752
- Radford, Alec, Metz, Luke, Chintala, Soumith, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”, arXiv preprint arXiv:1511.06434, 2015. https://arxiv.org/abs/1511.06434
- Ioffe, Sergey, Szegedy, Christian, “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”, International Conference on Machine Learning (ICML), 2015. https://arxiv.org/abs/1502.03167
- Zhang, Han, Goodfellow, Ian, Metaxas, Dimitris, Odena, Augustus, “Self-Attention Generative Adversarial Networks”, International Conference on Machine Learning (ICML), 2019. https://arxiv.org/abs/1805.08318
- Vaswani, Ashish, Shazeer, Noam, Parmar, Niki, Uszkoreit, Jakob, Jones, Llion, Gomez, Aidan N., Kaiser, Lukasz, Polosukhin, Illia, “Attention Is All You Need”, Advances in Neural Information Processing Systems (NeurIPS), 2017. https://arxiv.org/abs/1706.03762
- Karras, Tero, Aila, Timo, Laine, Samuli, Lehtinen, Jaakko, “Progressive Growing of GANs for Improved Quality, Stability, and Variation”, International Conference on Learning Representations (ICLR), 2018. https://arxiv.org/abs/1710.10196
- Ronneberger, Olaf, Fischer, Philipp, Brox, Thomas, “U-Net: Convolutional Networks for Biomedical Image Segmentation”, Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2015. https://arxiv.org/abs/1505.04597
- Isola, Phillip, Zhu, Jun-Yan, Zhou, Tinghui, Efros, Alexei A., “Image-to-Image Translation with Conditional Adversarial Networks”, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. https://arxiv.org/abs/1611.07004