Panorama de los seis paradigmas generativos modernos (autorregresivos, GANs, VAEs, basados en score, flujos y difusión), su orden histórico y un repaso autocontenido de probabilidades y redes neuronales.
Overview de los modelos generativos modernos
La inteligencia artificial ha pasado por diversas etapas históricas, incluyendo dos periodos conocidos como inviernos de la IA, caracterizados por una disminución considerable en la inversión y avances significativos en el área. Actualmente, podríamos afirmar que la IA vive su mejor momento, principalmente gracias al auge de arquitecturas neuronales eficientes, destacando especialmente los modelos tipo Transformer. Estos avances han sido impulsados por mejoras significativas en hardware (GPU) y una disponibilidad masiva de datos no supervisados, los cuales permiten, por ejemplo, preentrenar grandes modelos de lenguaje (LLMs) para que adquieran conocimiento del mundo.
En este primer capítulo se revisarán de forma general los distintos paradigmas generativos modernos, los cuales abarcan desde los modelos autorregresivos (usado en LLMs y agentes) hasta los modelos de difusión y flow matching (usado para la generación de imágenes y videos). En este capítulo también se entregará la notación utilizada a lo largo del libro, y se repasarán algunos conceptos básicos de probabilidades y redes neuronales, los cuales serán necesarios para el estudio de la IA generativa moderna, la cual tiene un enfoque completamente probabilístico.
Diariamente se publican cientos de artículos relacionados con IA, haciendo imposible revisar todas las contribuciones relevantes. En este libro, por lo tanto, se abordarán aquellos resultados considerados más fundamentales y relevantes, colocando énfasis en los principios subyacentes de la IA generativa más que en modelos específicos, los cuales tienden a evolucionar y quedar obsoletos rápidamente. Comprender estos principios resulta indispensable para distinguir entre el hype publicitario y las auténticas innovaciones científicas en este campo.
Por otro lado, entender en profundidad el funcionamiento interno de estos modelos permite implementar soluciones propias desde cero, lo cual es particularmente relevante en contextos donde la privacidad o la personalización resulta esencial para el trabajo que se busca realizar. Además, muchas veces los modelos del estado del arte son publicados únicamente con los pesos de las redes neuronales, sin incluir, por ejemplo, los loops de entrenamiento y/o inferencia, los cuales son indispensables para poder utilizar estos modelos en la práctica.
Qué puede generar un modelo generativo
Un modelo generativo es un tipo de modelo de machine learning cuyo objetivo es aprender la distribución subyacente de los datos, denotada como pdata(x), a partir de ejemplos generados por dicha distribución. Este aprendizaje permite generar nuevas muestras sintéticas que resultan similares a las utilizadas durante el entrenamiento. Usualmente, estos modelos son entrenados de manera no supervisada (o auto-supervisada), lo que ha permitido, por ejemplo, poder utilizar gran parte del contenido que hay internet para entrenar modelos de lenguaje o de visión.
El desarrollo de la IA generativa moderna comenzó alrededor del año 2014 con la aparición del autoencoder variacional (VAE) para imágenes [1] y los modelos seq2seq para texto [2]. Desde entonces, las capacidades de estos modelos han evolucionado rápidamente, alcanzando resultados que antes se creían exclusivos del ser humano. Algunas tareas que permiten resolver los modelos generativos actuales son las siguientes:
Creación y modificación de imágenes: inpainting (modificar solo una porción de una imagen), colorización (pasar una imagen en blanco y negro a color), superresolución (aumentar la resolución de una imagen), outpainting (extensión de imágenes más allá de sus bordes), mejora de calidad, interpolación semántica entre imágenes, transferencia de estilos, etc.
Tarea de transferencia de estilo. Imagen obtenida desde [4].
Generación de sonido y video: clonación de voz, composición musical, generación de videos a partir de descripciones textuales, extensión o edición de videos, etc.
Edición de video mediante un prompt. Imagen obtenida desde [5].
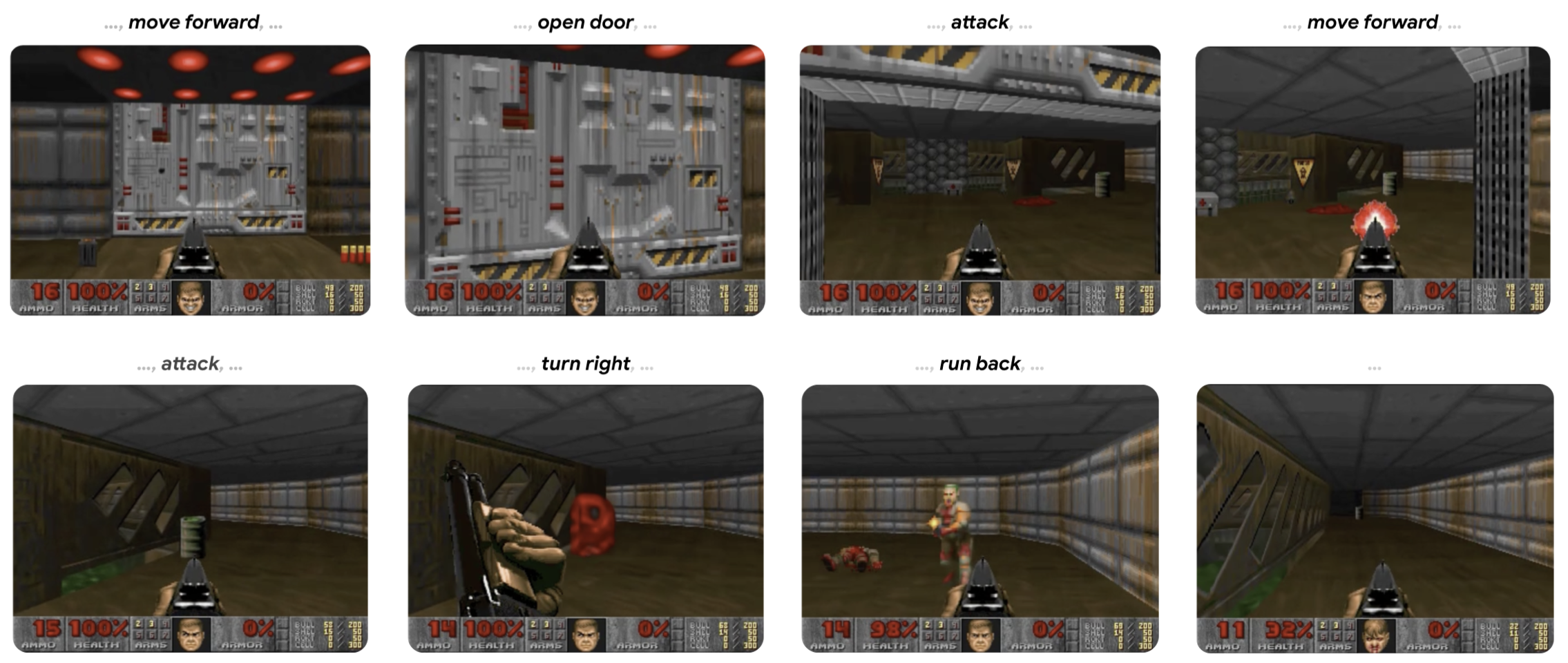
Simulaciones de juegos: generación de movimientos óptimos en ajedrez, NPCs personalizables, creación dinámica de escenarios de juego en tiempo real, etc. Más aún, este tipo de problemas puede ser incluido en una línea de investigación llamada world models [6], donde se busca modelar un ambiente completo, en el cual un agente puede tomar decisiones que influyen en el ambiente y en su propio estado interno.
Simulación del juego DOOM con creación de ambiente en tiempo real. Imagen obtenida desde [7].
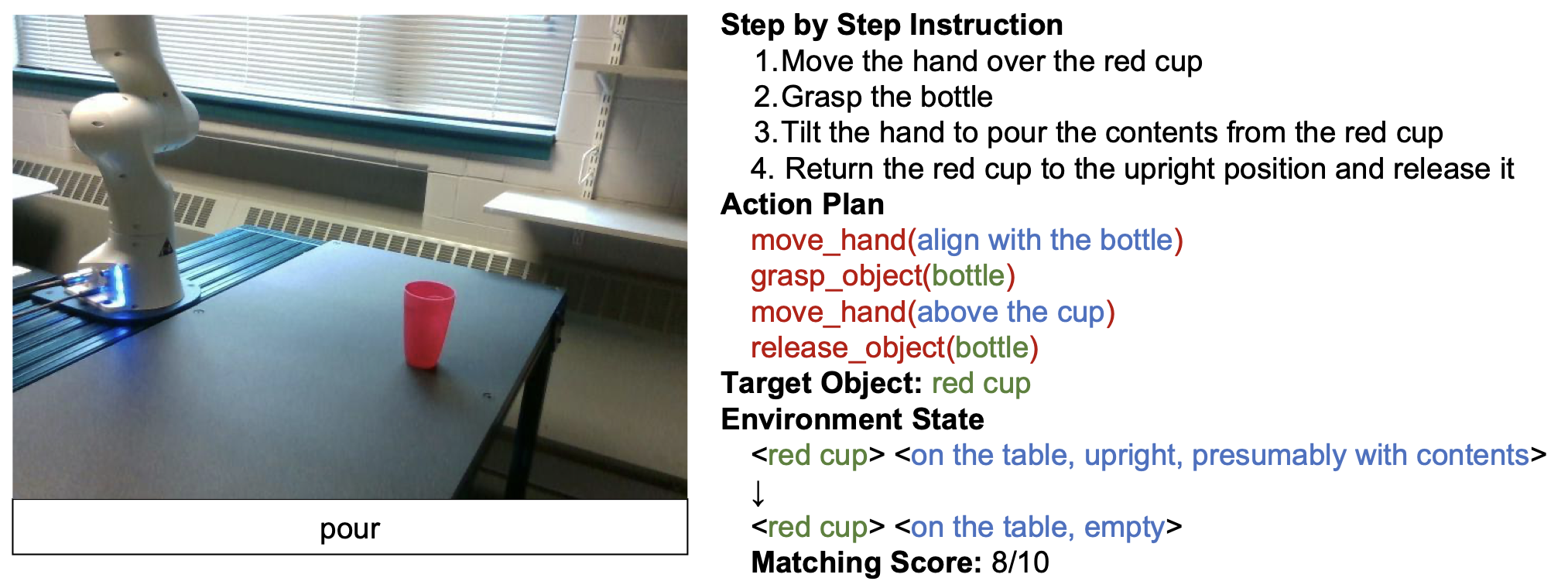
Robótica potenciada por LLMs: uso de modelos tipo GPT para que robots interpreten y ejecuten instrucciones dadas en lenguaje natural.
Robot usando un LLM para resolver una tarea. Imagen obtenida desde [8].
Predicción de estructuras moleculares: diseño de fármacos, predicción del plegamiento de proteínas (como AlphaFold [9], reconocido con el premio Nobel de Química en 2024), generación de secuencias genéticas y creación de nuevos materiales con propiedades avanzadas (e.g., más resistentes o con capacidad autoregenerativa), etc.
Modelo de difusión utilizado para la generación molecular. Imagen obtenida desde [10].
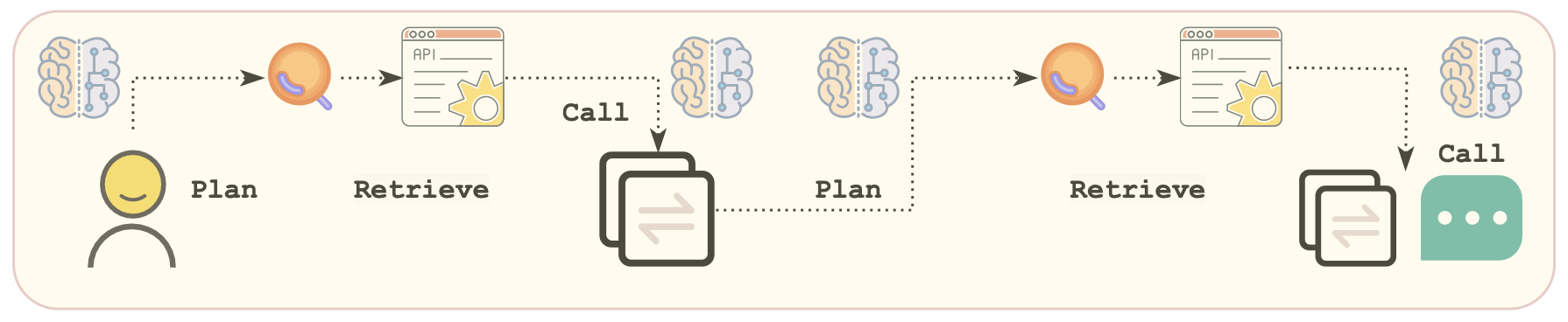
Agentes autónomos: planificación para lograr un objetivo, uso de herramientas, análisis y toma de decisiones, etc.
Planificación y uso de herramientas para completar una tarea. Imagen obtenida desde [11].
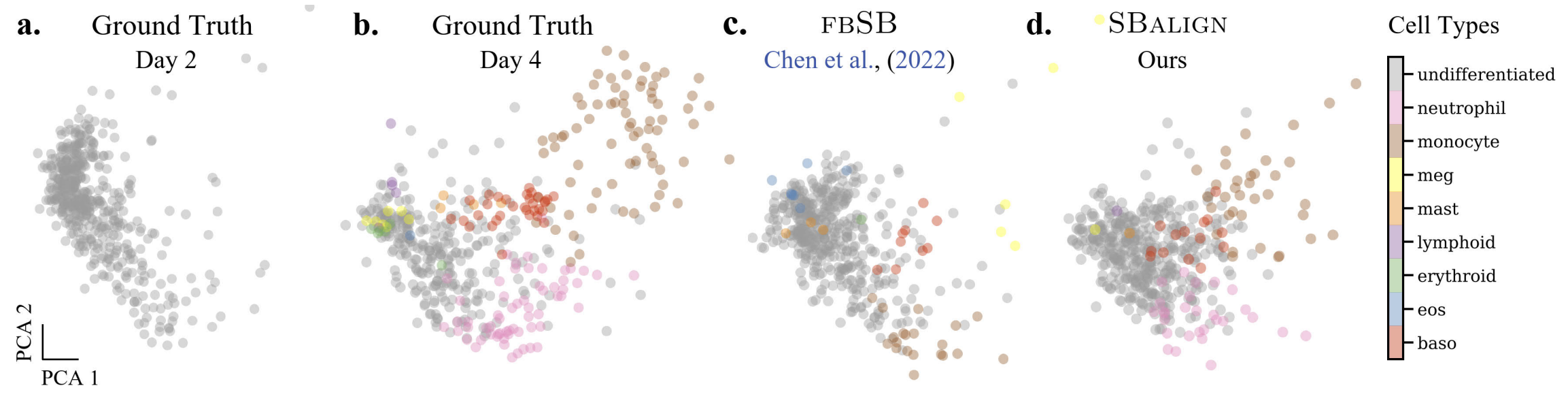
Investigaciones científicas: predicción de estados cerebrales, simulación de procesos de diferenciación celular, demostración automática de teoremas, modelos del clima, resolución numérica de ecuaciones diferenciales parciales (EDPs), detección de anomalías astronómicas, etc.
Predicción de diferenciación celular usando puentes de Schrödinger. Imagen obtenida desde [12].
Si bien todas estas tareas parecen ser muy diferentes entre sí, todas comparten los mismos principios subyacentes para su resolución mediante modelos generativos. Es esperable que en un futuro no muy lejano, los modelos generativos puedan aplicarse para otro tipo de problemas como la creación de nuevos sabores y olores, fabricación de medicamentos personalizados, estudio de teorías científicas novedosas, implantación de recuerdos artificiales e incluso formas de vida alternativas. Del mismo modo, este tipo de modelos podrá, eventualmente, contribuir al desarrollo de nuevos sistemas políticos para mejorar la gobernanza, formular estrategias económicas innovadoras, e incluso encontrar soluciones a grandes problemas como lo es el calentamiento global o la hambruna en países menos desarrollados.
Perspectivas para estudiar los modelos generativos
Los modelos generativos actuales pueden ser estudiados desde distintos ángulos, por ejemplo:
Perspectiva económica y política: consumo energético y monetario (e.g., se estima que entrenar GPT 4 costó 78 millones de dólares y generó lo equivalente a 15 mil toneladas de CO2). Por otro lado, el 2024 Joe Biden declaró a la IA como un asunto de seguridad nacional, mientras que el 2025, Donald Trump anunció una inversión de 500 mil millones de dólares en IA con el proyecto Stargate (comparar, por ejemplo, con el programa Apolo, en el cual se invirtieron 180 mil millones de dólares).
Perspectiva ética: sesgos (género, raza, políticos), mal uso (deepfake, filtración de datos, ataques terroristas, ataques adversarios) e infracciones de copyright (diseño, libros, música, intelectual, etc.).
Interés filosófico: cómo definir AGI/ASI, qué es inteligencia, entender, pensar o sentir.
Interés teórico: ¿puede un modelo realmente crear algo nuevo o solo interpola lo que aprendió? ¿Es posible evitar la alucinación de los LLMs? Los modelos de difusión, autoencoders variacionales y modelos basados en flujos tienen muy buen background matemático, lo que permite estudiar más fácilmente sus propiedades teóricas (e.g., existen resultados de convergencia, generalización a otros espacios y extensión a variedades diferenciables). Sin embargo, el entendimiento de los LLMs es muy limitado hoy en día, por lo que la mayoría de propiedades conocidas en este tipo de modelos son solo empíricas, sin ningún fundamento técnico que garantice la presencia o ausencia de estas propiedades.
En este libro solo se mencionarán algunos de estos puntos, sin entrar en detalle en ninguno de ellos ya que hoy en día no hay un consenso claro acerca de estos temas. Es esperable que en los próximos años se sigan desarrollando estos temas y se obtenga la madurez y robustez suficiente para estudiar estos tópicos de manera más formal.
Paradigmas modernos de la IA generativa
La inteligencia artificial generativa ha avanzado enormemente en la última década (e.g., en 2019, GPT 2 no podía contar hasta 10 de forma correcta), impulsada principalmente por el desarrollo de modelos cada vez más potentes, los cuales consiguen realizar tareas que antes solo se creían posible para los humanos. Sin embargo, muchos de estos modelos modernos se forman ensamblando sub-modelos, muchas veces entrenados de forma independiente, donde cada uno se especializa en una tarea específica. Por ejemplo, para generar una imagen a partir de un texto descriptivo, el modelo DALL-E 2 de OpenAI [13] combina un modelo autorregresivo tipo Transformer para procesar el texto y luego utiliza un modelo de difusión para generar la imagen usando el texto procesado.
Por otro lado, cada uno de estos modelos individuales que componen un modelo mayor, suelen seguir alguno de los paradigmas modernos de IA generativa, los cuales son principalmente 6 (ordenados, a mi juicio, de forma ascendente en dificultad):
Modelos autorregresivos.
Redes generativas adversarias.
Autoencoders variacionales.
Modelos basados en score.
Modelos basados en flujo.
Modelos de difusión.
Es importante mencionar que tanto los modelos basados en flujo como los modelos de difusión pueden ser formulados en su versión temporal continua, lo cual aumenta considerablemente su dificultad y desarrollo. A continuación se describirá de forma general cada uno de estos paradigmas, los cuales serán estudiados en detalle en las próximos capítulos.
Modelos autorregresivos
Este es el paradigma generativo de facto para la generación de texto (aunque en los últimos años también se han propuesto enfoques basados en difusión). El enfoque autorregresivo consiste en ir generando cada palabra de una secuencia de texto de forma individual, utilizando las palabras ya generadas anteriormente. Más precisamente, si (x1,…,xt) es la secuencia de tokens (e.g., palabras o letras) generadas hasta el instante t∈N, un modelo autorregresivo generará la siguiente palabra xt+1 usando una red neuronal que toma como entrada las t palabras anteriores, (x1,…,xt).
Una característica importante de este tipo de modelos es que también pueden, a priori, procesar otro tipo de secuencias como secuencias de sonido (e.g., para generar música), secuencias temporales (e.g., para predecir variaciones en los mercados), o secuencias de aminoácidos (e.g., para generar proteínas biológicamente plausibles), siempre y cuando se encuentre una forma eficiente de obtener un vector de embedding (i.e., una representación vectorial) para el tipo de dato que se esté utilizando. Además, hoy en día las redes neuronales utilizadas en este paradigma suelen ser de tipo Transformer [14] ya que esta arquitectura ha mostrado funcionar mejor que otras arquitecturas anteriores como la GRU [15] o la LSTM [16].
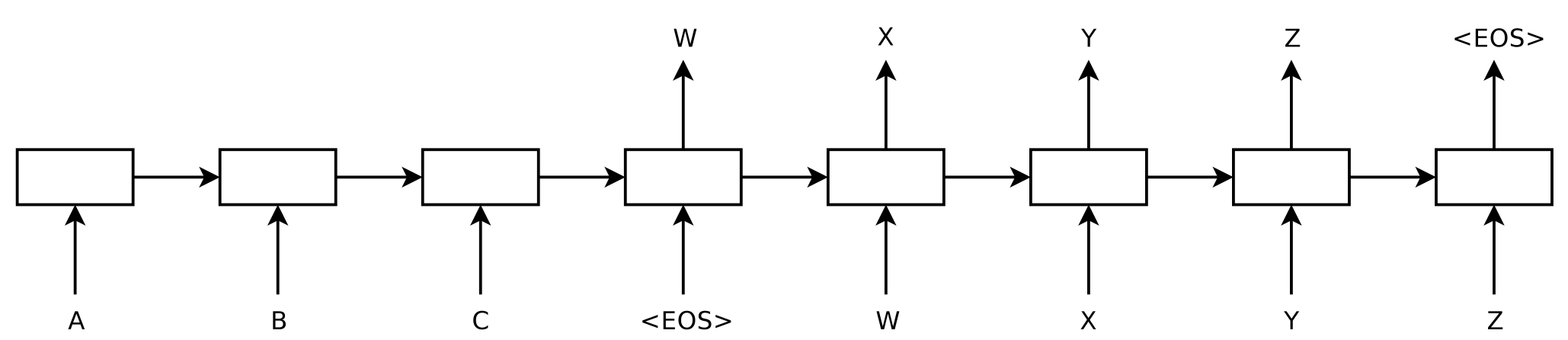
Modelo seq2seq, donde la entrada inicial (prompt) es ABC y la secuencia generada de forma autorregresiva es WXYZ. Imagen obtenida desde [2].
Redes generativas adversarias
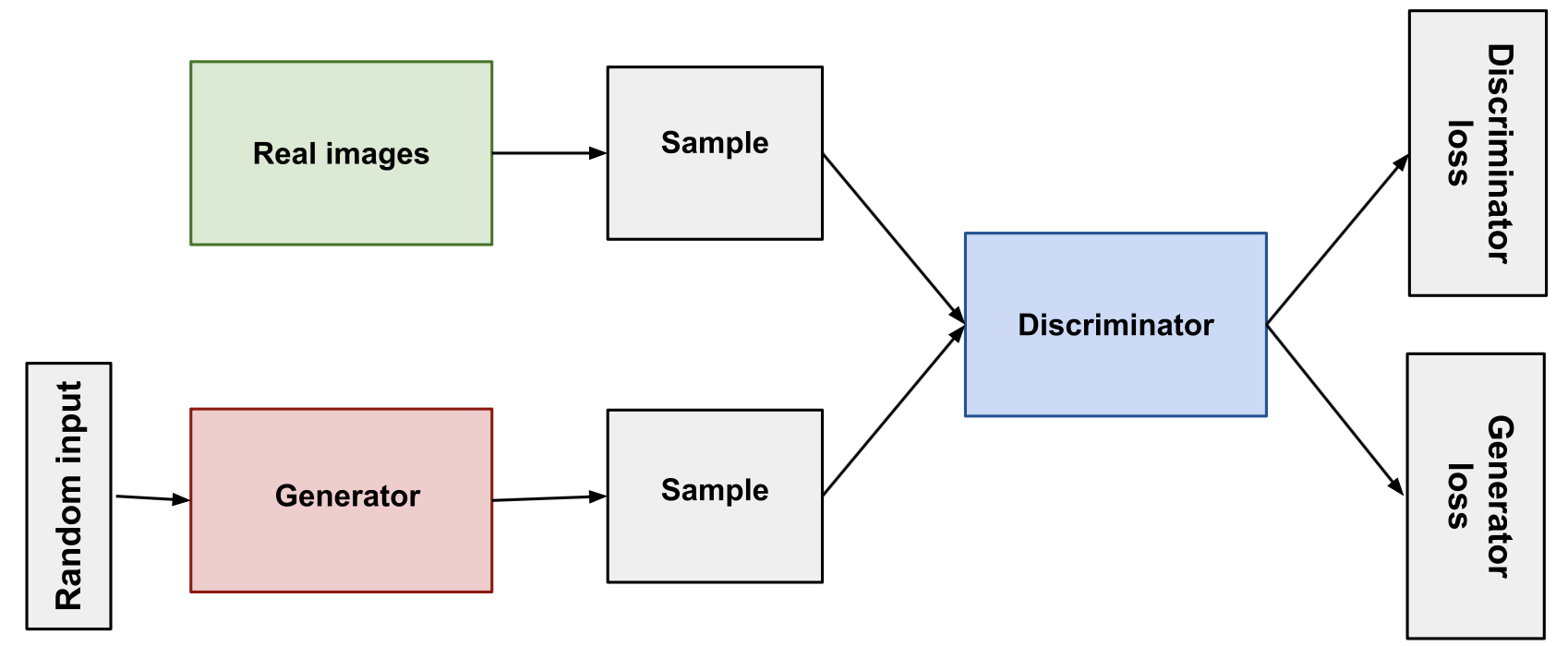
Las redes generativas adversarias (GANs) están formadas por dos componentes. El primer componente es una red neuronal discriminativa (i.e., un clasificador) que busca reconocer si la muestra x que recibe como entrada es una imagen real o una imagen generada artificialmente. El segundo componente (generador) es otra red neuronal que busca aprender a generar muestras x similares a las que hay en el conjunto de entrenamiento (el clasificador debería diferenciar este tipo de muestras de las muestras reales si estuviese bien entrenado). Para lograr esto, el modelo generador es entrenado buscando que el modelo discriminativo se equivoque. Luego del entrenamiento, se desecha el modelo discriminador y solo se conserva el modelo generador, el cual aprendió a generar muestras similares a las que se usaron durante el entrenamiento.
Dada la naturaleza competitiva de las GANs (red generadora vs. red discriminadora), el entrenamiento de este tipo de modelos es muy inestable y, de hecho, el valor de la función objetivo puede divergir. Si bien se han propuesto técnicas para aminorar estos problemas, las GANs también tienen otros problemas como aprender a generar siempre una misma imagen que se sabe que es capaz de engañar al clasificador. Problemas de esta naturaleza también provocan que las GANs no cubran, por lo general, todo el soporte de la distribución, concentrando su proceso de generación en una región pequeña del soporte real (mode collapse). Sin embargo, este fue el paradigma principal para generar imágenes antes de la llegada de los modelos de difusión.
Un modelo discriminativo (clasificador) aprende a diferenciar muestras reales de muestras generadas aleatoriamente. Imagen obtenida desde [17].
Autoencoders variacionales
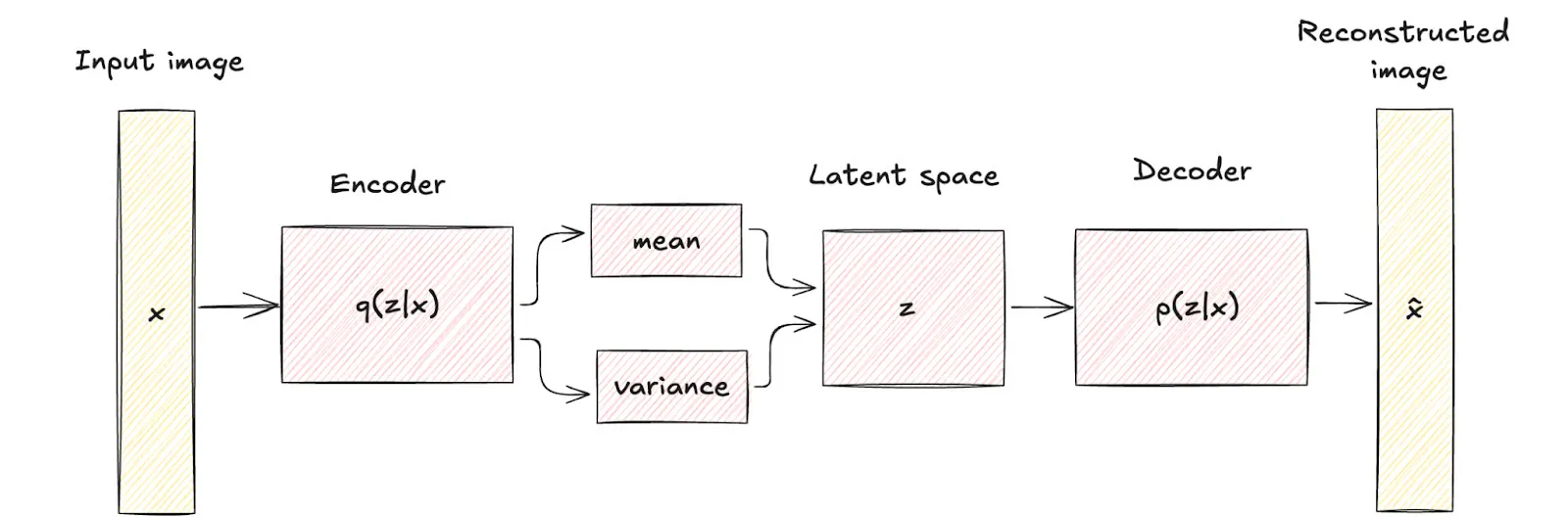
Los autoencoders variacionales (VAEs) son modelos generativos que permiten codificar una entrada x (e.g., una imagen) en un vector latente z (más precisamente, en una distribución qϕ(z∣x)), el cual luego puede ser decodificado para reconstruir la muestra original (usando una distribución pθ(x∣z)). La red neuronal que realiza la transformación x↦z se llama encoder, mientras que la red neuronal que realiza la transformación z↦x se llama decoder. Ambas redes se entrenan de manera conjunta, optimizando una cantidad conocida como ELBO, la cual funciona como una función objetivo proxy al objetivo clásico de máxima verosimilitud.
Una vez el VAE está entrenado, es posible generar una nueva muestra x comenzando con un vector latente inicial z cualquiera, y pasando este vector por el decoder z↦x.
El encoder de un VAE predice la media y varianza de una variable latente z gaussiana. Por otro lado, el decoder aprende a reconstruir la imagen a partir de la variable latente que generó el encoder. Imagen obtenida desde [18].
Modelos basados en score
Los modelos basados en energía (EBMs) consisten en modelar la función de densidad pθ(x) mediante otra cantidad Eθ(x) llamada energía. Este cambio de variable permite saltarse las restricciones típicas que se tienen al modelar directamente una distribución de probabilidad (positividad y que integre 1), las cuales suelen ser difíciles de imponer en una red neuronal.
Si bien este tipo de modelos puede ser estudiado desde una perspectiva más clásica (e.g., estudiando máquinas de Boltzmann), el enfoque moderno consiste en reformular estos modelos para que aprendan la cantidad ∇xlogpθ(x) (llamada score) en vez de la función de energía. Si bien por ahora no son claras las ventajas de conocer esta cantidad, este gradiente resultará ser muy importante para poder realizar generación condicional en los modelos de difusión.
Modelos basados en flujo
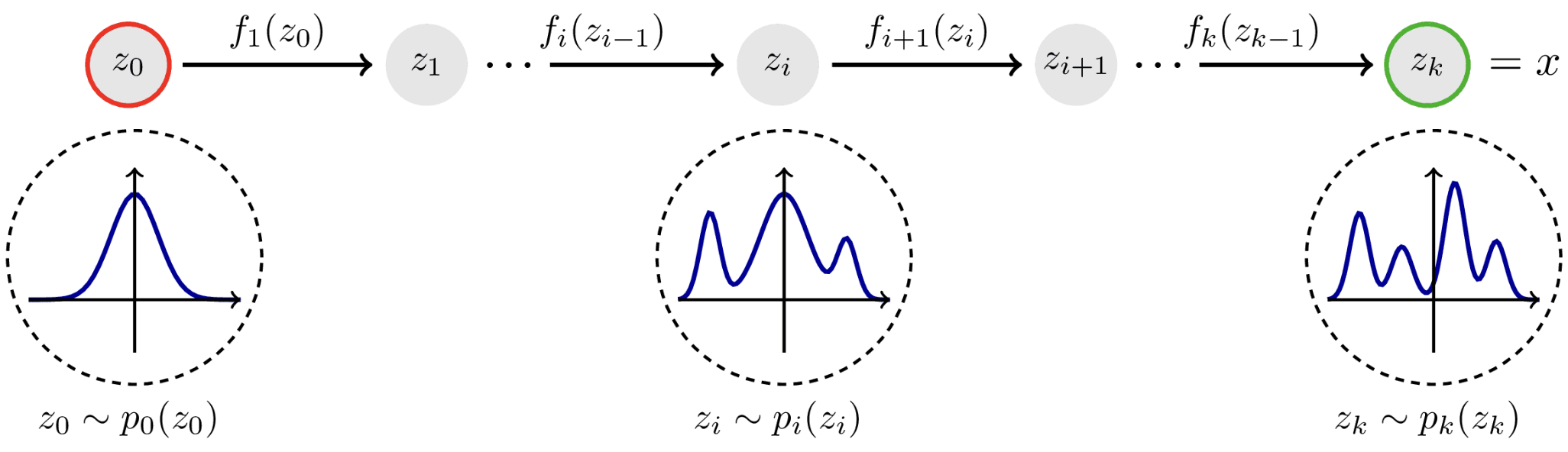
Esta familia de modelos consiste en aplicar consecutivamente un conjunto de funciones simples para poder transformar un ruido inicial z0 (e.g., una muestra gaussiana) en una muestra de la distribución pdata(x) que se quiere aprender. El principal problema de este paradigma es que las funciones que se aplican deben ser invertibles (de hecho, se verá que deben ser difeomorfismos), lo cual es una restricción difícil de conseguir en una red neuronal.
Por otro lado, su formulación a tiempo continuo (donde la dinámica de evolución viene dada por una ecuación diferencial ordinaria) no tiene este tipo de restricciones y, de hecho, tiene muy buenas propiedades. Las técnicas de flow matching [19] y rectified flows [20] son ejemplos de modelos basados en flujo a tiempo continuo, las cuales se podrían considerar como el estado del arte actual para la generación de imágenes y video (ver, por ejemplo, FLUX.1 Kontext [21]).
Transformación de un ruido gaussiano inicial en una muestra de la distribución que se busca aprender. Imagen obtenida desde [22].
Modelos de difusión
Los modelos de difusión consisten en corromper una imagen inyectándole ruido de forma progresiva, para así entrenar un modelo neuronal que aprenda a deshacer el ruido inyectado (modelo de denoising). La cantidad de iteraciones de inyección de ruido debe ser suficientemente grande para que, en el último paso, la imagen corrompida sea similar a una muestra gaussiana. De esta forma, con el modelo de denoising ya entrenado, es posible generar una nueva imagen comenzando desde una muestra gaussiana inicial, para luego aplicar el modelo de denoising de forma iterativa hasta llegar a una imagen sin ruido.
Proceso de denoising de un modelo de difusión. Imagen obtenida desde [23].
Orden histórico de los paradigmas modernos
Tal como se suele considerar que AlexNet [24] (2012) marcó el comienzo de la revolución del deep learning, se puede considerar que los autoencoders variacionales [1] (finales del 2013) marcaron el comienzo de la IA generativa moderna (aunque también se podría considerar otros modelos como las GANs [25] o los modelos seq2seq [2]). El siguiente diagrama temporal permite poner en contexto algunos de los trabajos más importantes de cada paradigma generativo. Notar que también se incluyen algunos trabajos fundacionales de deep learning como lo es la técnica de dropout [26] o el optimizador Adam [27]:
En esta sección se definirá la notación general usada a lo largo del libro y se repasarán algunos conceptos de probabilidades y redes neuronales que serán utilizados en el estudio de los distintos paradigmas generativos. Otros conceptos más específicos y ortogonales a la IA generativa serán estudiados en las capítulos respectivos donde se utilicen. Por ejemplo, los LLMs hacen uso de técnicas de reinforcement learning, mientras que las GANs pueden vincularse con conceptos de teoría de juegos. Por otro lado, los modelos basados en energía, los VAEs y los modelos de difusión tiene conexiones con la física estadística y termodinámica mediante la distribución de Boltzmann y la energía libre de Helmholtz. Además, muchos de los paradigmas a estudiar pueden ser conectados con tópicos de transporte óptimo cuando se estudian con suficiente profundidad.
A lo largo de todo el libro, Mm,n(R) denotará el conjunto de matrices de tamaño m×n (con valores en R), mientras que los vectores se considerarán siempre verticales (RD≅MD,1(R)). La matriz identidad de tamaño n×n, 10⋮001⋮0⋯⋯⋱⋯00⋮1∈Mn,n(R) será denotada por In. Para dos vectores x,y∈RD, su producto punto x⋅y=∑d=1Dxdyd será denotado por ⟨x,y⟩, mientras que la notación x⊙y∈RD representará el producto de Hadamard, es decir, el producto coordenada a coordenada: (x⊙y)d=xdyd para d∈{1,…,D}.
Para un conjunto finito A, su cardinal (i.e., cantidad de elementos) será denotado por ∣A∣. Para dos conjuntos A y B, el producto cruz A×B={(a,b):a∈A,b∈B} representará el conjunto de todos los posibles pares que se pueden formar con elementos de A y B, mientras que la notación f:A→B indicará una función con dominio A y codominio B. Por otro lado, para a,b∈R, la notación a≪b indicará que a es mucho menor que b (análogo para ≫). Además, los logaritmos serán considerados siempre naturales (i.e., con base e). En particular, los conceptos de teoría de la información (e.g., entropía) serán medidos en nats. La notación de superíndice (e.g., x1,…,xN) será usada para indexar un conjunto de N∈N elementos, y no debe confundirse con el operador potencia. En cambio, la notación de subíndice (e.g., x1,…,xD) por lo general será usada para recorrer las componentes de un vector x∈RD.
En cuanto a operadores diferenciales, para un campo escalar f:RD→R, su gradiente será denotado como ∇xf(x):=∂x1∂f(x)⋮∂xD∂f(x)∈RD, mientras que para un campo vectorial F:RN→RM su matriz jacobiana será denotada como DxF(x):=∇xF1(x)⊤⋮∇xFM(x)⊤∈MM,N(R) (i.e., para F(x)=(F1(x),…,FM(x)), cada entrada es (DxF(x))ij=∂xj∂Fi(x)).
Probabilidades
De manera informal, una variable aleatoriax es una función que puede tomar distintos valores de acuerdo a una distribución de probabilidadp(x), la cual se interpreta de dos formas distintas, dependiendo de si se está trabajando con una variable aleatoria discreta o continua. En ambos casos, p(x) corresponde a una función asociada a la probabilidad de que x tome cierto valor. De esta forma, para indicar que x sigue una distribución de probabilidad p(x), se suele escribir x∼p(x), independientemente de si la variable aleatoria es discreta o continua.
El conjunto donde p(x) es positivo se denomina soporte, supp(x):={x:p(x)>0}, e indica los distintos valores que una variable aleatoria puede tomar. Cuando el soporte de una variable aleatoria es finito (i.e., ∣supp(x)∣<∞), la variable aleatoria se dice discreta, y p(x) se llama función de masa ya que indica cuánta masa (probabilidad) le asigna la variable aleatoria a cada elemento del soporte. Por otro lado, si x es una variable aleatoria en RD que puede tomar una cantidad continua de valores, entonces la variable aleatoria se dice continua, y p(x) se llama función de densidad. El cambio de nombre en ambos casos se debe a que, si bien p(x) tiene el mismo propósito en ambos casos, la forma de operar con p(x) cambia dependiendo de si se está trabajando con una variable discreta o una variable continua.
Si bien se pueden combinar ambos tipos de variables para trabajar con un tipo de dato mixto (discreto y continuo), no suele ser necesario revisar esta extensión para el estudio de los modelos generativos, lo cual requeriría introducir algunos conceptos de teoría de la medida. En consecuencia, siempre se asumirá que cada variable aleatoria es, o bien discreta, o bien continua.
Variables aleatorias discretas
Si x∼p(x) es una variable aleatoria discreta con supp(x)={k1,…,kN}, entonces la función de masa p(x) es una función p:{k1,…,kN}→[0,1], la cual indica la probabilidad de que x tome un cierto valor de su soporte, es decir, Prob(x=kn)=p(kn). Notar que, por definición de medida de probabilidad, es necesario que p(kn)≥0 y que ∑n=1Np(kn)=1.
Por otro lado, la igualdad p(kn)=Prob(x=kn) muchas veces motiva a usar la notación p(x=kn), la cual es útil para evitar ambigüedades cuando se está trabajando con más de una variable aleatoria. Además, dado que el soporte es finito, se pueden almacenar todas las salidas de la función de masa p(x) en un vector de probabilidades(p(k1),…,p(kN))∈[0,1]N, el cual muchas veces, y abusando de notación, es denotado también por p.
A lo largo de todo el libro, se denotará como ΔN al N-símplex, el cual es el conjunto de vectores de probabilidad de largo N∈N:
La distribución discreta más simple es la distribución de Bernoulli, en la cual la variable aleatoria x solo puede tomar los valores 0 y 1. Esta distribución permite modelar escenarios donde solo puede haber dos resultados distintos y excluyentes, como en el lanzamiento de una moneda, o el éxito/fracaso de algún experimento.
Se dice que x∼Bernoulli(r), con r∈[0,1], si supp(x)={0,1} con Prob(x=1)=r y Prob(x=0)=1−r, es decir:
p(x)={r1−rsi x=1si x=0=rx(1−r)1−x,x∈{0,1}
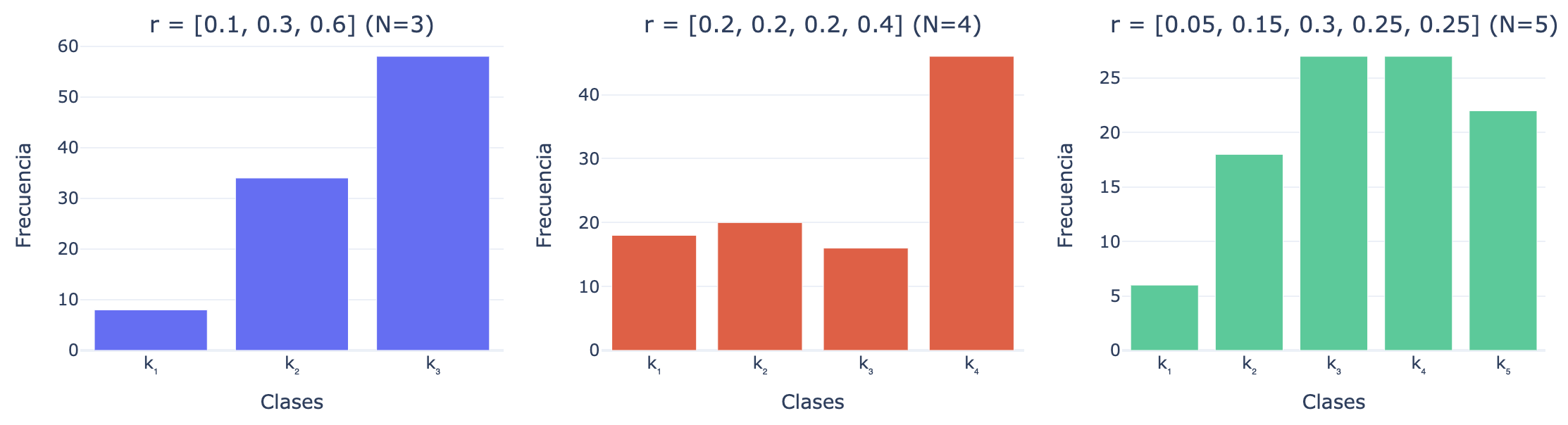
La distribución categórica es la extensión natural de la distribución de Bernoulli al caso donde la variable aleatoria puede tomar N posibles valores. Se dice que x∼Categoˊrica(r), con r∈ΔN, si supp(x)={k1,…,kN} y Prob(x=kn)=rn, es decir, p(kn) es la k-ésima coordenada del vector r. En el siguiente gráfico se pueden ver 100 muestras generadas para 3 distribuciones categóricas distintas. Se observa que los 3 gráficos de frecuencia son consistentes con la función de masa p(x) que induce cada vector de probabilidades r∈Δ3:
100 muestras generadas para tres distribuciones categóricas con distintos vectores de probabilidad r∈Δ3.
Si bien la distribución categórica es lo suficientemente general para englobar todas las distribuciones posibles de variables aleatorias discretas, hay algunos casos particulares frecuentes, los cuales reciben nombres distintivos (e.g., la distribución binomial). Además, también es usual incluir dentro de las distribuciones discretas a aquellas variables aleatorias que pueden tomar una cantidad infinita numerable (no continua) de valores (e.g., supp(x)=N para la distribución de Poisson). Sin embargo, no será necesario considerar estos casos para los temas que se estudiarán a lo largo del libro.
Variables aleatorias continuas
Cuando se trabaja con variables aleatorias continuas, es usual considerar que estas son no atómicas, es decir, la probabilidad de tomar un valor en específico es siempre 0 (e.g., si se elige al azar un número en el intervalo [0,1], la probabilidad de elegir exactamente el valor 0.8 es cero). Por lo tanto, para este tipo de variables, lo que se suele calcular es la probabilidad de que la variable aleatoria tome un valor dentro de un conjunto de posibles valores. Más precisamente, si x∼p(x) es una variable aleatoria continua en RD (i.e., supp(x)⊂RD es no numerable), entonces la función de densidad p(x) es una función p:RD→R+, la cual permite calcular la probabilidad de que x esté en un cierto conjunto A⊂RD mediante integración:
Prob(x∈A)=∫Ap(x)dx
Notar que, por definición de probabilidad, la función de densidad p(x) necesariamente debe cumplir que ∫RDp(x)dx=1, lo cual corresponde a la probabilidad calculada sobre todo el soporte de la variable aleatoria. Por ejemplo, para D=1, la función de densidad
p(x)={4210−x20si x∈[−3,3]si x∈/[−3,3]
es efectivamente una función de densidad (con supp(x)=[−3,3]) ya que
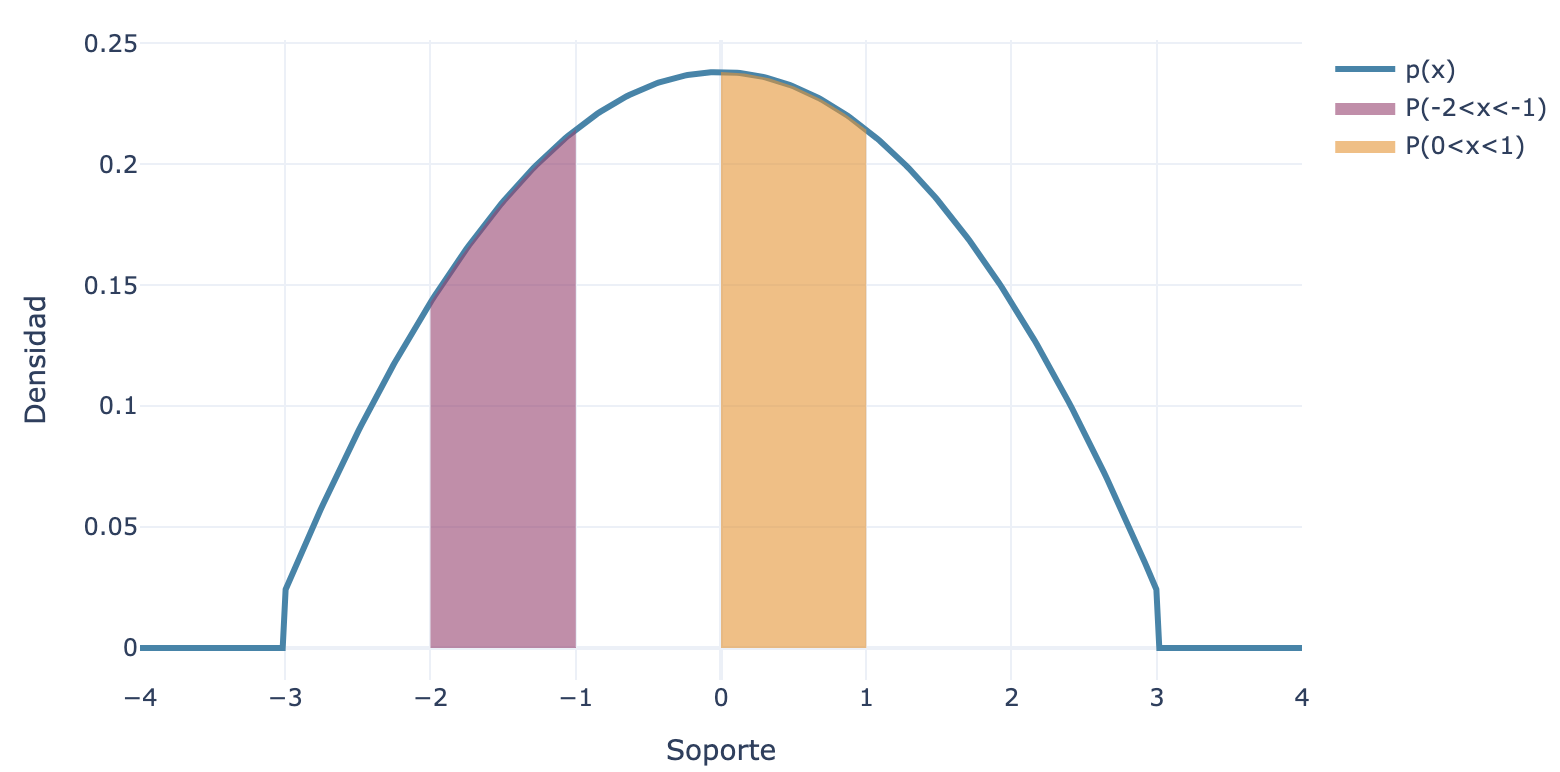
Notar que la división por 42 se realiza únicamente para forzar que la función p(x) integre 1 (sin esta normalización, la integral daría 42). Por otro lado, dado que la probabilidad de que x∈[a,b] es Prob(a≤x≤b)=∫abp(x)dx, se puede calcular, por ejemplo, que Prob(−2≤x≤−1)≈0.18<0.23≈Prob(0≤x≤1), lo cual es directo de ver al notar que el área bajo la función de densidad que cubre el intervalo [−2,−1] es menor al área que cubre el intervalo [0,1]:
Función de densidad p(x)=(10−x2)/42 sobre [−3,3], con las áreas correspondientes a Prob(−2≤x≤−1) y Prob(0≤x≤1).
Por lo general, nunca será necesario calcular estas integrales a mano ya que se casi siempre se trabajará, al menos en este libro, con la distribución gaussiana, la cual tiene buenas propiedades que evita tener que calcular integrales (además, la densidad gaussiana no tiene primitiva analítica, por lo que habría que recurrir a métodos numéricos para el cálculo de integrales gaussianas). Por otro lado, notar que las funciones de densidad no poseen la restricción p(x)≤1, para todo x∈RD ya que p(x) no representa directamente una probabilidad (como sí ocurre con las funciones de masa en el caso discreto).
Por otra parte, muy pocas veces se tendrá que D=1 ya que, usualmente, la dimensión del espacio sobre el que se definirán distribuciones de probabilidad es considerablemente alto (e.g., para imágenes, cada canal de cada pixel cuenta como una dimensión diferente). Por lo tanto, la tarea de modelar distribuciones en estos espacios es una tarea no trivial debido a que, para muchos métodos estadísticos clásicos, es usual encontrarse con la maldición de la dimensionalidad, la cual provoca que algunos problemas no se puedan resolver eficientemente en alta dimensión, ya sea porque se necesita una cantidad exponencial de datos para obtener buenos estimadores, o bien porque se necesita una cantidad exponencial de tiempo para resolver el problema.
La distribución gaussiana (o distribución normal) es una distribución de probabilidad definida sobre todo R (i.e., su soporte es (−∞,∞)), cuya función de densidad viene dada por
p(x)=2πσ21exp(−2σ21(x−μ)2),
donde μ∈R y σ2>0 son dos parámetros que definen diferentes distribuciones gaussianas, por lo que se suele denotar x∼N(μ,σ2) para diferenciarlas. Posteriormente, se verá que μ resulta ser el valor esperado de la distribución, mientras que σ2 resulta ser su varianza (o, equivalentemente, σ es su desviación estándar). Además, notar que el único rol de la constante 2πσ21>0 es, al igual que en el ejemplo anterior, normalizar la función de densidad para que ∫Rp(x)=1 (esto se puede verificar con un cambio de variables a coordenadas polares). Por lo tanto, la parte que define el comportamiento de la distribución gaussiana es el término exponencial. Se observan varias cosas:
La exponencial de una cantidad negativa (en este caso, −2σ21(x−μ)2) decae muy rápido, por lo que la masa (probabilidad) suele estar concentrada en una porción pequeña del espacio (se dice que la gaussiana es una distribución de cola ligera, a diferencia de otras distribuciones que decaen más lento y son de cola pesada).
El valor máximo de exp(−x) se alcanza en x=0, por lo que la masa de la distribución p(x) está concentrada alrededor del punto x=μ. Más aún, como este máximo es único (p(x) es estrictamente cóncava), la distribución es unimodal (i.e., hay un único punto con mayor densidad).
Como p(x) es una función simétrica con respecto a μ (i.e., p(x−μ)=p(μ−x)), el gráfico de p(x) es simétrico con respecto a μ.
A medida que aumenta el valor del parámetro σ2>0, el término 2σ21(x−μ)2 se vuelve más chico, por lo que la densidad p(x) decae más lento. En consecuencia, el gráfico es menos empinado ya que la masa se reparte de manera más uniforme entre el soporte.
Si bien la función exponencial decae rápido, p(x)>0 para todo x∈R (i.e., supp(x)=R), por lo que todo punto de R tiene probabilidad positiva de ser generado por una distribución gaussiana, aunque para puntos muy alejados de μ, la probabilidad es extremadamente baja si el parámetro σ2 es pequeño.
La probabilidad del evento x∈A (para A⊂R) está dada por la integral ∫A2πσ21exp(−2σ21(x−μ)2)dx, cuyo valor no se puede obtener de forma cerrada (ya que no existe una forma analítica para ∫ex2dx). En consecuencia, para calcular probabilidades sobre esta distribución se suelen usar algoritmos numéricos para aproximar la integral.
Si bien el cálculo de probabilidades requiere integración numérica, es útil recordar algunas probabilidades típicas asociadas a la distribución gaussiana. Mediante integración se puede calcular la probabilidad de que una variable gaussiana no se desvíe más allá de una cierta cantidad de su valor medio μ. Para x∼N(μ,σ2), se puede probar que:
Prob(∣x−μ∣≤σ)≈68%
Prob(∣x−μ∣≤2σ)≈95%
Prob(∣x−μ∣≤3σ)≈99.8%
Estas probabilidades permiten tener una noción acerca de las regiones donde se concentrarán las muestras generadas a partir de una variable aleatoria x∼N(μ,σ2).
Dado que la distribución gaussiana es no atómica (i.e., no le asigna masa a puntos individuales), los resultados anteriores siguen siendo válidos si se consideran las desigualdades de manera estricta (i.e., cambiando ≤ por <). De hecho, para distribuciones no atómicas siempre se tendrá que Prob(x≤t)=Prob(x<t) (y, por lo tanto, también se tendrá que Prob(x≥t)=Prob(x>t) ya que Prob(x≥t)=1−Prob(x<t)).
Con respecto a la generación de muestras desde una distribución gaussiana, se conocen varios métodos para hacerlo, siendo el método de Box-Muller el más usual. En este libro, se asumirá que siempre se pueden generar (y de forma eficiente) muestras desde una distribución normal ya que los paquetes de Python que se usarán (e.g., NumPy o PyTorch) tienen implementados estos métodos.
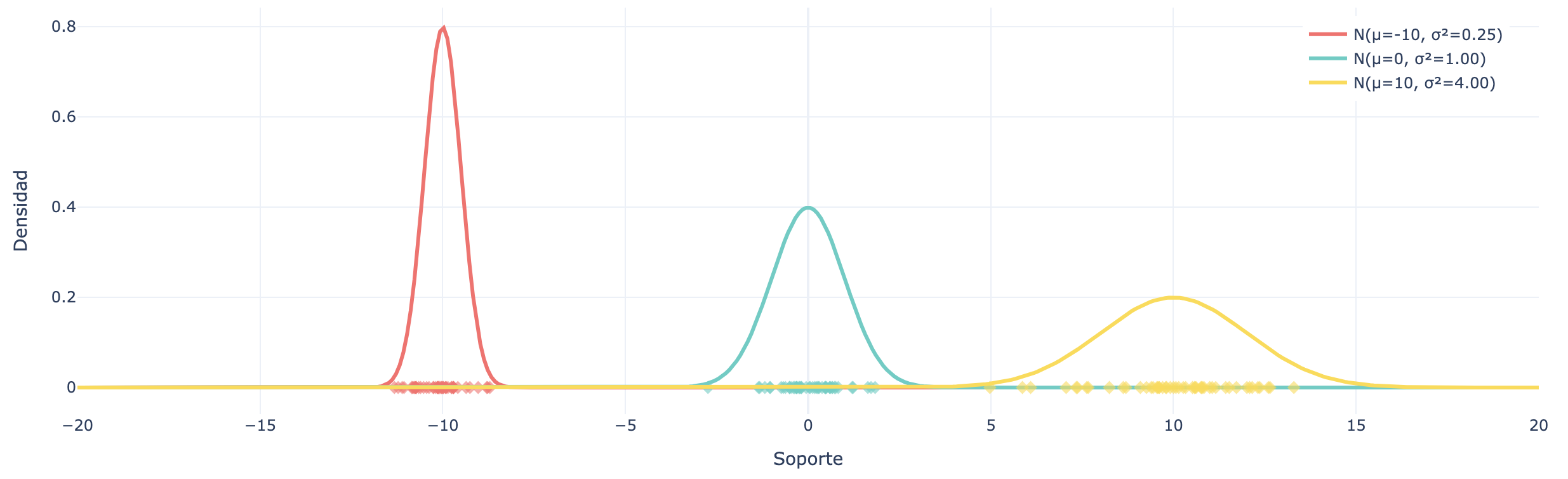
En la siguiente figura se observan 3 distribuciones gaussianas diferentes, con 50 muestras generadas desde cada distribución. Se observa que para un valor σ2>0 pequeño, la mayor parte de las muestras está concentrada de la media, mientras que para valores más altos, las muestras generadas oscilan en un rango mayor.
50 muestras generadas desde 3 distribuciones gaussianas con distintos valores de σ2.
La distribución gaussiana es, por lejos, la distribución más popular entre todas las distribuciones de probabilidad que existen. Esto se debe, en parte, a que esta distribución tiene muy buenas propiedades que la hacen una elección cómoda para trabajar, además de que suele estar presente en muchos resultados teóricos en probabilidades (e.g., en el teorema central del límite). Algunas propiedades que serán útiles a lo largo del libro son las siguientes:
Sus parámetros μ y σ2 son totalmente interpretables. Más precisamente, el parámetro μ corresponde a la esperanza de la distribución, mientras que el parámetro σ2 corresponde a su varianza.
Si x∼N(μ,σ2), entonces ax+b∼N(aμ+b,a2σ2), es decir, trasladar afínmente una v.a. gaussiana x equivale a trasladar afínmente la función de media y ponderar cuadráticamente su varianza.
Si x1∼N(μ1,σ12) y x2∼N(μ2,σ22), entonces x1+x2∼N(μ1+μ2,σ12+σ22). En particular, la familia de variables aleatorias gaussianas es cerrada bajo la suma (i.e., la suma de gaussianas es gaussiana).
Su función de densidad es fácil de optimizar. Más precisamente, logp(x) es una función cóncava (por lo que la función p se dice log-cóncava), lo que implica que no hay máximos locales donde quedarse atrapado durante la maximización de logp(x), la cual es precisamente la función objetivo del enfoque de máxima verosimilitud que se estudiará al revisar redes bayesianas.
El promedio de variables aleatorias i.i.d. converge (en distribución) a una variable aleatoria gaussiana. Esto se conoce como el teorema del límite central y es uno de los motivos por el cual la distribución gaussiana aparece en tantos lugares, muchas veces de manera inesperada.
Es la distribución de máxima entropía dentro de la familia de distribuciones cuyo soporte es todo R (y que además tienen varianza finita). Esto se puede interpretar diciendo que la distribución gaussiana es la que más aleatoriedad tiene o la distribución que menos información a priori asume cuando se interpreta como el prior de una variable aleatoria, lo cual es usual en modelos generativos de variable latente.
Existen todos sus momentos: los conceptos de esperanza y varianza pueden ser extendidos a un concepto más general denominado momento. La distribución gaussiana tiene bien definidos todos sus momentos, lo cual no es algo que siempre ocurra y muchas veces es una propiedad deseable, ya sea por temas prácticos (e.g., para conocer más información de la variable aleatoria) o temas teóricos (la existencia de los momentos muchas veces es una hipótesis necesaria en teoremas de probabilidades y teoría de la medida).
Es posible extender la distribución gaussiana al caso multidimensional, D>1. Una forma fácil es considerar una variable aleatoria x=(x1,…,xD) en RD, donde cada componente sigue una distribución gaussiana (i.e., xd∼N(μd,σd2) para todo d∈{1,…,D}). Esto se suele denotar como x∼N(μ,Σ), donde ahora μ=(μ1,…,μD)∈RD es el vector de medias, mientras que la matriz diagonal Σ=diag(σ12,…,σD2)∈MD,D(R) almacena las varianzas de cada coordenada. En general, esta matriz puede no ser diagonal, pero siempre debe ser simétrica (i.e., Σ=Σ⊤) y definida positiva (i.e., sus valores propios son todos positivos) o, al menos, semidefinida positiva si se permite el caso degenerado, donde la variable aleatoria se vuelve determinista en alguna(s) dirección(es) del espacio. Sin embargo, siempre se asumirá que Σ es no degenerada ya que esto permite poder definir una función de densidad. En este caso, la función de densidad de una variable aleatoria x=(x1,…,xD)∼N(μ,Σ) es
p(x)=(2π)Ddet(Σ)1exp(−21(x−μ)⊤Σ−1(x−μ)),
donde det(Σ)>0 es el determinante de la matriz Σ∈MD,D(R). Notar la similitud de esta función de densidad con la función de densidad de la gaussiana unidimensional: la constante (2π)Ddet(Σ)1>0 es la constante de normalización para que ∫RDp(x)dx=1, mientras que la forma cuadrática dentro de la exponencial es una extensión de la cantidad σ2(x−μ)2 en la gaussiana unidimensional. Más aún, cuando Σ=σ2ID (se dice que la gaussiana es esférica o isotrópica), se tiene que 2−1(x−μ)⊤Σ−1(x−μ)=2σ2−1∥x−μ∥2, obteniendo la generalización natural de la cantidad −2σ21(x−μ)2. Por otro lado, la matriz Σ−1 está bien definida ya que la matriz Σ es invertible por ser una matriz definida positiva. Si Σ solo fuera semidefinida positiva (i.e., si 0 es un valor propio de Σ), la matriz no sería invertible y la función de densidad p(x) no estaría definida. Estos casos no se considerarán en el libro, por lo que se puede asumir siempre que la función de densidad existe.
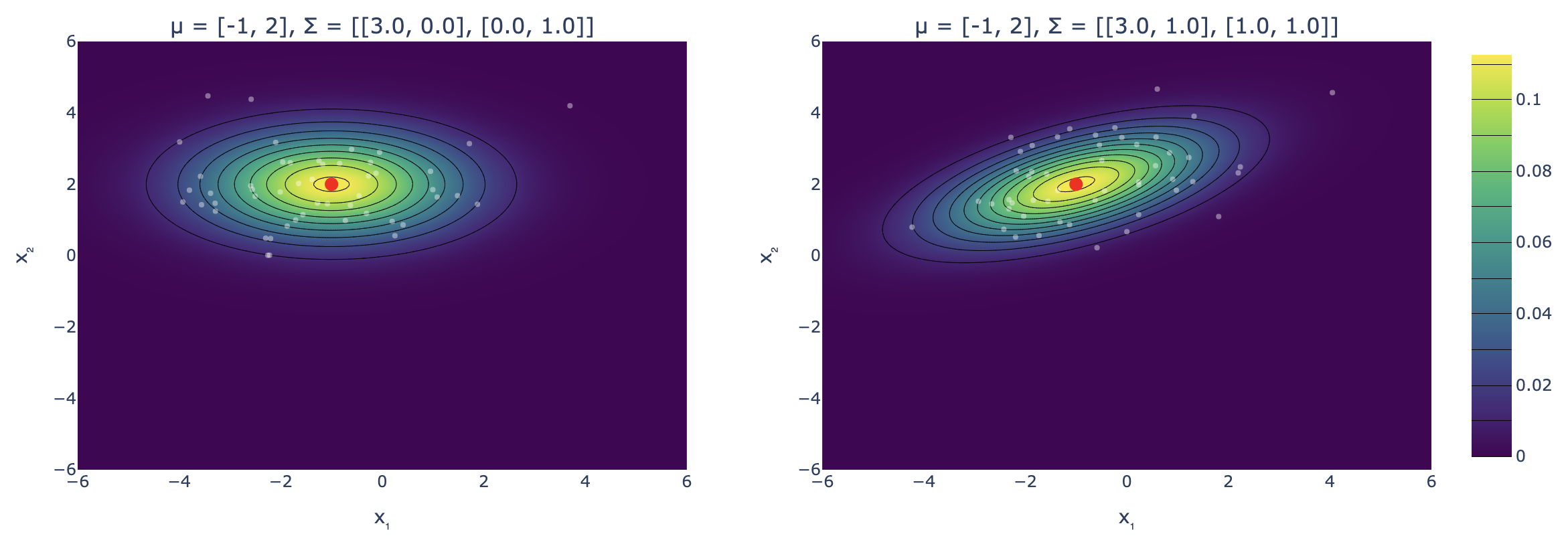
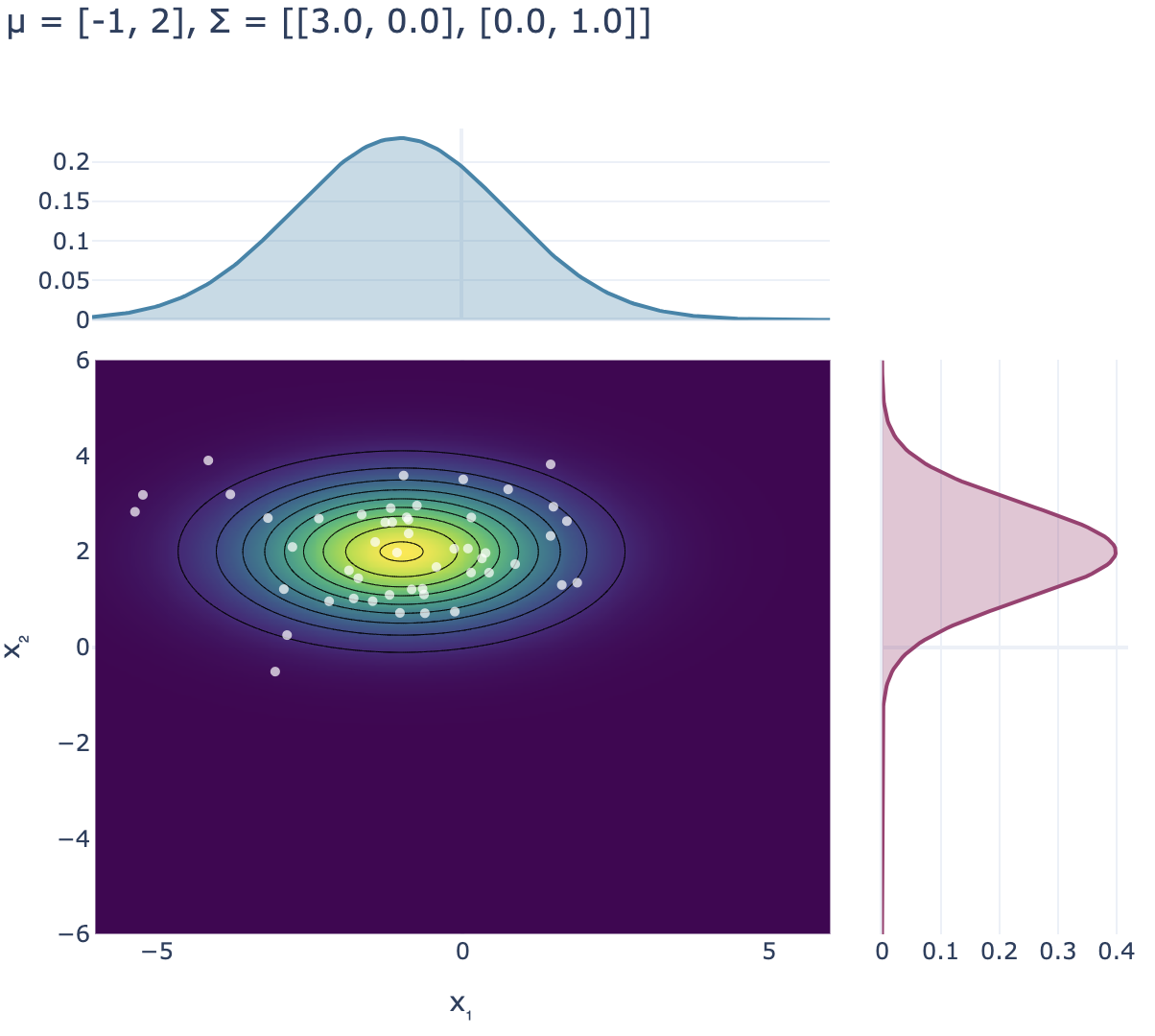
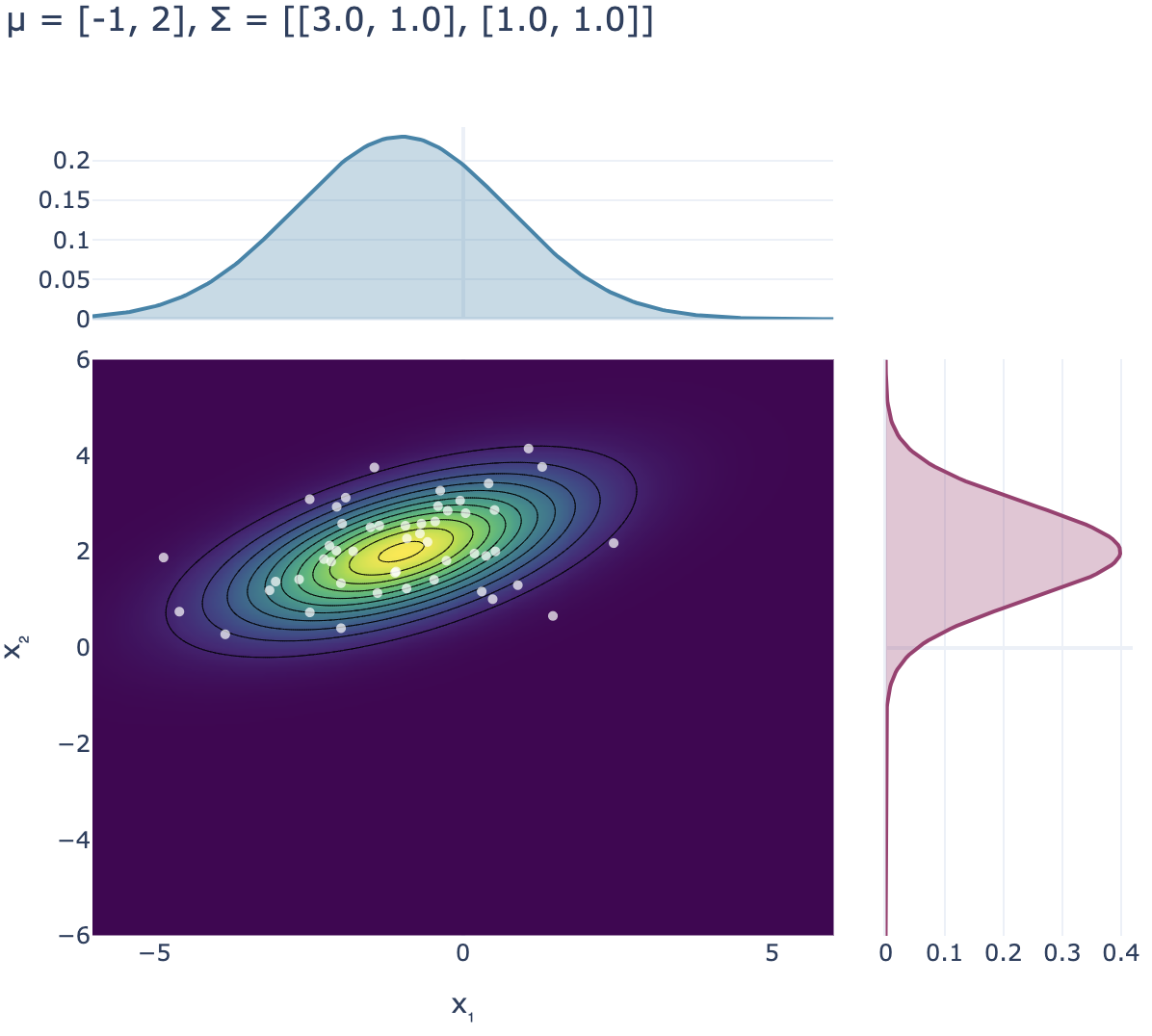
En la siguiente figura, el gráfico de la izquierda muestra la función de densidad y algunas muestras de una gaussiana bidimensional x∼N(μ,Σ) con μ=(−1,2)⊤ y Σ=(3001), es decir, x1∼N(−1,3) y x2∼N(2,1). Se observa que la primera componente de las muestras son más dispersas, lo que se debe a que la varianza de x1 es mayor que la varianza de x2. Además, las curvas de nivel de p(x) (conjunto de puntos que tienen la misma densidad) forman elipses alrededor de la media. El hecho de que estas elipses no estén inclinadas (sus semi-ejes son paralelos a los ejes cartesianos) se debe a que las componentes de x=(x1,x2) fueron definidas de forma independiente (Σ es matriz diagonal), por lo que el valor de una no influye en el valor de la otra (en particular, conocer el valor de una de las coordenadas no entrega ninguna información sobre el valor de la otra coordenada). Cuando las coordenadas de una variable aleatoria están relacionadas entre sí, se dice que hay una noción de dependencia entre ellas, ya que el valor de una componente afecta el valor de la otra. Este comportamiento se puede ver en el gráfico de la derecha, donde ahora se considera Σ=(3111). Notar que el hecho de que esta matriz no sea diagonal induce una rotación en el mapa de calor asociado a la función de densidad, lo cual podría justificarse estudiando la cónica que induce la forma cuadrática asociada a la función de densidad de una gaussiana multivariable. Sin embargo, más abajo se precisará bien qué indican los valores fuera de la diagonal principal de Σ.
Funciones de densidad y muestras para dos gaussianas bidimensionales: a la izquierda, con matriz de covarianza diagonal; a la derecha, con componentes dependientes.
Probabilidad condicional y dependencia
En modelos complejos donde hay muchas variables aleatorias interactuando entre sí, es usual conocer algunos valores de esas variables aleatorias debido a que sus valores ya fueron determinados (i.e., el experimento aleatorio que definía su valor ya ocurrió y se conoce su resultado) o bien, fueron impuestos por algún motivo. A modo de ejemplo, se puede considerar un modelo de dos variables aleatorias, x=(x1,x2)∼p(x1,x2), donde x1 es una variable aleatoria que indica si una persona lleva paraguas (x1=1) o no (x1=0), mientras que x2 indica si llueve (x2=1) o no (x2=0). Por lo general, el valor más probable para x1 es 0 (asumiendo que por lo general no llueve), pero esto cambia si se sabe que x2=1 ya que, en este caso, aumenta considerablemente la probabilidad de que x1=1. Es decir, la distribución de x1 cambia si se conoce el valor de x2, por lo que se dice que x1 depende de x2.
Dadas dos variables aleatorias, x∼p(x) e y∼p(y), la notación p(x∣y) corresponde a la distribución que sigue la variable aleatoria x cuando se conoce el valor de la variable aleatoria y. Esta función (de masa en el caso discreto y de densidad en el caso continuo) está definida como
p(x∣y):=p(y)p(x,y)
Notar que esta definición tiene sentido: conocer el valor de y limita el posible espacio de valores que puede tomar la variable x (lo cual se refleja imponiendo el valor de y en la distribución conjunta p(x,y)), mientras que la división por p(y) busca normalizar la nueva distribución para x, recortando el espacio muestral únicamente a aquellos eventos donde y toma el valor indicado. Por ejemplo, en el caso anterior, la variable aleatoria que indica si una persona lleva paraguas o no en un día lluvioso es p(x1∣x2=1)=p(x2=1)p(x1,x2=1), donde p(x1,x2=1) es la probabilidad de que la persona lleve paraguas (o no) y que además esté lloviendo, mientras que p(x2=1) es la probabilidad de que esté lloviendo, sin considerar si la persona lleva paraguas o no.
Dos variables aleatorias x∼p(x) e y∼p(y) se dicen independientes (denotado como x⊥y) si el valor de una no influye en el otro, es decir: p(x∣y)=p(x). Notar que, por definición de probabilidad condicional, esto indica que p(x)=p(y)p(x,y), por lo que x⊥y es equivalente a que p(x,y)=p(x)p(y). Esto muestra, además, que la independencia es simétrica, es decir, si x⊥y, entonces y⊥x (i.e., p(y∣x)=p(y)). Si dos variables aleatorias no son independientes, se dice que son dependientes. Por ejemplo, si x es una variable aleatoria discreta asociada a lanzar una moneda e y es una variable aleatoria discreta asociada a lanzar un dado, dado que ambas variables son independientes entre sí, la probabilidad de que la moneda salga cara y en el dado salga un 4 es Prob(x=cara,y=4)=Prob(x=cara)⋅Prob(y=4)=21⋅61=121, lo cual es consistente con la probabilidad que se obtiene al trabajar con la distribución conjunta, donde el total de pares (moneda,dado) posibles es 2⋅6=12, mientras que la cantidad de pares favorables es 1 (solo uno de los pares tiene x=cara∧y=4), por lo que, por la regla de Laplace, Prob(x=cara,y=4)=121.
Cuando se tiene una distribución conjuntap(x,y) (i.e., la función de masa o de densidad asociada a cada combinación (x,y) de valores que pueden tomar las variables aleatorias), es posible conocer la distribución marginalp(x), la cual corresponde a la distribución que sigue la variable aleatoria x de forma independiente, sin saber el valor que toma y (lo que ocurre, por ejemplo, cuando y es una variable oculta). Para esto, es necesario sumar (o integrar en el caso continuo) sobre todos los posibles valores que puede tomar la variable aleatoria y. En el caso discreto, si supp(y)={y1,…,yN}:
p(x)=n=1∑Np(x,y=yn)
Por ejemplo, para la gaussiana bidimensional usada más arriba, donde x∼N(μ,Σ) con μ=(−1,2)⊤ y Σ=(3001), ambas distribuciones marginales, p(x1) y p(x2), siguen una distribución gaussiana, donde cada media está contenida en el vector de media μ y las varianzas vienen dadas en la diagonal de la matriz de covarianzas Σ. Esto mismo ocurre para la segunda variable aleatoria que se consideró, la cual tenía una matriz de covarianzas Σ=(3111), mostrando que el único efecto de los valores fuera de la diagonal de Σ es rotar el elipsoide generado para inducir dependencia entre las componentes de la distribución. En la siguiente figura se vuelven a visualizar ambas funciones de densidad, donde además se agregan las densidades marginales de cada componente:
Gaussiana bidimensional con Σ diagonal y sus distribuciones marginales.
Gaussiana bidimensional con componentes dependientes y sus distribuciones marginales.
Se observa que las marginales en ambos casos coinciden, aunque la distribución conjunta no sea la misma. Esto muestra que la distribución conjunta p(x,y) contiene más información que las distribuciones individuales p(x) y p(y) ya que al marginalizar se pierden las nociones de dependencia entre ambas variables. Sin embargo, si las variables x e y son independientes, entonces p(x,y)=p(x)p(y) por lo que, en este caso, las distribuciones marginales contienen la misma información que la distribución conjunta.
Una consecuencia directa de la definición de probabilidad condicional es el cálculo de distribuciones posteriores. Dado que p(x,y)=p(x)p(y∣x) y p(x,y)=p(y)p(x∣y), entonces se tiene que
p(y∣x)=p(x)p(y)p(x∣y)
Esta propiedad se conoce como regla de Bayes, y permite calcular la distribución posteriorp(y∣x) conociendo únicamente la distribución condicional opuesta, p(x∣y), y las marginales p(x) y p(y). Por ejemplo, un análisis estadístico simple puede permitir estimar la probabilidad de que una persona enferma tenga tos, por lo que, usando la regla de Bayes, se podría estimar la probabilidad de que una persona con tos esté enferma. Es importante mencionar que el hecho de usar la regla de Bayes no tiene relación alguna con ser bayesiano ya que esto último es simplemente una decisión filosófica acerca de cómo interpretar las probabilidades (más precisamente, de cómo interpretar los axiomas de Kolmogorov), donde la probabilidad representa el grado de confianza o creencia en la ocurrencia de un evento, a diferencia del enfoque frecuentista, donde la probabilidad de un evento corresponde a la regla de Laplace cuando la cantidad de experimentos tiende a infinito.
Por otro lado, la propiedad p(x,y)=p(x)p(y∣x) puede ser extendida a un conjunto de variables aleatorias, donde la distribución conjunta se descompone en un producto de probabilidades condicionales. En efecto, se puede probar por inducción que
Esta propiedad se conoce como regla de la cadena (de las probabilidades), y no debe confundirse con la regla de la cadena de las derivadas.
Esperanza y varianza
En esta sección se estudiarán los conceptos de esperanza y varianza, los cuales son casos específicos de un concepto más general llamado momento. Tanto la esperanza como la varianza jugarán un rol fundamental en todos los paradigmas generativos que se estudiarán.
Dada una variable x∼p(x), su esperanza o valor esperado corresponde al valor que uno esperaría obtener al promediar muchas muestras generadas desde x. Si x∼p(x) es una variable discreta con supp(x)={k1,…,kN}, su esperanza se define como la suma ponderada sobre su soporte, donde el ponderador de cada sumando corresponde a la masa del respectivo átomo:
Ex∼p(x)[x]:=n=1∑Nknp(x=kn)
Por ejemplo, si x∼Bernoulli(r), entonces Ex∼p(x)[x]=0⋅p(x=0)+1⋅p(x=1)=r, lo cual es lo esperado cuando se interpreta la distribución de Bernoulli como el lanzamiento de una moneda cargada. De forma más general, para una función genérica f:{k1,…,kN}→R, se tiene que Ex∼p(x)[f(x)]=∑n=1Nf(kn)⋅p(x=kn).
En el caso continuo donde p:RD→R+ es una función de densidad, la esperanza de la variable aleatoria x∼p(x) se define de forma análoga:
Ex∼p(x)[x]:=∫RDxp(x)dx
De forma general, se tiene que Ex∼p(x)[f(x)]=∫RDf(x)p(x)dx. A lo largo del libro, usualmente se denotará Ex∼p(x)[x] como Ep(x)[x] para no sobrecargar la notación. Más aún, cuando no hay ambigüedad, se suele denotar simplemente como E[x], aunque se evitará esta notación ya que puede ser poco didáctica.
Por otro lado, si una variable aleatoria no participa dentro del argumento de la esperanza, se puede omitir su referencia:
En la segunda igualdad se usó que p(x,y)=p(x)p(y∣x) junto con el teorema de Fubini, mientras que en la tercera igualdad se usó que ∫RDp(y∣x)dy=1 ya que p(y∣x) es una densidad de probabilidad (con respecto a y). Usando esta propiedad, es directo ver que la esperanza es un operador lineal. En efecto, para α,β∈R:
Ep(x)[αf(x)+βg(x)]=αEp(x)[f(x)]+βEp(x)[g(x)]
De hecho, si x e y son variables independientes, también se tiene que Ep(x,y)[xy]=Ep(x)[x]Ep(y)[y] (la recíproca no es cierta: poder separar el producto no implica independencia). Además, la definición de esperanza permite escribir el proceso de marginalización descrito anteriormente como una esperanza:
Esta expresión tiene sentido ya que consiste en promediar todas las posibles densidades que tendría x para los distintos valores que puede tomar y.
Un problema que muchas veces provoca confusión es reconocer cuál es la variable aleatoria con la que se está tomando esperanza. Por ejemplo, en la expresión Ep(x∣y)[f(x,y)], la variable aleatoria es x y su distribución, p(x∣y), asume que y es un valor fijo y conocido (i.e., Ep(x∣y)[f(x,y)] es una función de y). Si y también es una variable aleatoria con y∼p(y), se puede promediar la esperanza anterior sobre los posibles valores de y, lo que resulta ser equivalente a calcular la esperanza de la distribución conjunta:
Más en general, la esperanza sobre un conjunto de variables aleatorias se puede factorizar de manera análoga a como se pueden factorizar las distribuciones conjuntas usando la regla de la cadena. Esta propiedad será importante para el desarrollo de los modelos generativos ya que permitirá, por ejemplo, escribir expresiones como
Dada la importancia de la esperanza en el desarrollo de los modelos generativos (y en machine learning en general), es importante poder calcular esta cantidad de forma eficiente (e.g., para entrenar una red neuronal). Si bien muchas veces esto no es posible, la ley de los grandes números permite aproximar esta cantidad utilizando muestras de la distribución con respecto a la que se calcula la esperanza. Más precisamente, si x∼p(x) es una variable aleatoria desde la cual es fácil generar muestras, entonces
Ep(x)[f(x)]≈N1n=1∑Nf(xn),dondexn∼p(x), para todo n∈{1,…,N}
Esta aproximación se suele llamar estimación de Monte Carlo, y solo requiere poder generar muestras desde p(x). Además, este promedio es un estimador insesgado y consistente para la esperanza Ep(x)[f(x)], por lo que la aproximación mejora a medida que se utilizan más muestras desde p(x). Sin embargo, en los modelos que se revisarán será usual utilizar una única muestra para la estimación.
La varianza de una variable aleatoria x∼p(x) en R corresponde a la desviación (cuadrática) media de la variable aleatoria con respecto a su media μ=Ep(x)[x]. Por lo tanto, la varianza es una medida de dispersión o aleatoriedad de la variable aleatoria:
La primera igualdad es la definición usual de varianza, mientras que la última igualdad es una expresión equivalente que resulta ser útil en algunos casos. A modo de ejemplo, si x∼Bernoulli(r), recordando que Ep(x)[x]=r, entonces Var(x)=(0−r)2p(x=0)+(1−r)2p(x=1)=r(1−r).
Una pregunta natural es por qué considerar en la definición la desviación de la media elevada a 2 y no considerar solamente la desviación absoluta Ep(x)[[x−μ]]. La respuesta más simple a esto es porque es conveniente: definir la varianza usando un exponente cuadrático permite obtener buenas propiedades matemáticas. Por ejemplo, si x e y son variables aleatorias independientes, entonces se puede probar que Var(αx+βy)=α2Var(x)+β2Var(y), lo cual no sería cierto si se considera otro exponente. Este fenómeno también se ve en otros lugares: al momento de definir la distribución gaussiana se utiliza una diferencia cuadrática dentro de la función exponencial y no simplemente el valor absoluto (como sí lo hace la distribución de Laplace) ya que el exponente cuadrático le da buenas propiedades a la distribución normal (e.g., diferenciabilidad). Esto también se observa al realizar regresión lineal basada en mínimos cuadrados, donde esta elección permite encontrar el regresor óptimo de forma cerrada.
Por otro lado, el concepto de varianza puede extenderse al concepto de covarianza, el cual permite comparar dos variables aleatorias. Si x∼p(x) e y∼p(y) son dos variables aleatorias en R con medias μx y μy respectivamente, la covarianza entre x e y mide el grado de desviación conjunta de cada variable con respecto a sus medias:
Cov(x,y):=Ep(x,y)[(x−μx)(y−μy)]
Notar que si x aumenta/disminuye su valor al mismo tiempo que y aumenta/disminuye su valor, entonces hay una covarianza positiva, mientras que si una de las variables aumenta su valor cuando la otra variable disminuye (o viceversa), entonces se tiene una covarianza negativa. En particular, Cov(x,x)=Var(x)≥0.
Por otra parte, notar que Cov(x,y)=0 no implica necesariamente que x⊥y ya que la covarianza solo puede captar relaciones lineales entre las variables (e.g., si (x,y)∈R2 representan coordenadas de un círculo unitario, Cov(x,y)=0 pero las variables sí estarán relacionadas ya que x2+y2=1).
En general, cuando se tiene un vector aleatorio x=(x1,…,xD)∼p(x), es posible construir su matriz de covarianzas Cov(x)∈MD,D(R) cuyas entradas son Cov(x)ij:=Cov(xi,xj). En particular, la diagonal de esta matriz contiene las varianzas de cada componente de x. Además, notando que Cov(xi,xj)=Cov(xj,xi), se tiene que la matriz de covarianzas siempre es simétrica.
Por otro lado, la magnitud de Cov(x,y) no indica el grado de relación entre las variables ya que la covarianza depende fuertemente de la escala de los valores que toman las variables x y y. Sin embargo, el coeficiente de correlación de Pearson normaliza esta cantidad para tener un valor más interpretable:
ρ(x,y):=Var(x)Var(y)Cov(x,y)∈[−1,1]
En esta definición, la cantidad ∣ρ(x,y)∣∈[0,1] indica el grado de correlación entre las variables. Un valor ρ(x,y) cercano a 1 indica una dependencia casi lineal entre las variables, mientras que un valor más cercano a 0 indica un patrón más difuso entre las variables aleatorias.
Redes neuronales
Una red neuronal es una función f:RD→RC que se puede entrenar (i.e., se puede cambiar su comportamiento) para aprender a replicar otra función fpdata:RD→RC, usualmente desconocida, utilizando un conjunto de entrenamiento D={(x1,y1),…,(xN,yN)}⊂RD×RC, donde cada instancia de entrenamiento (xn,yn) es de la forma yn=fpdata(xn). De este modo, cuando la red neuronal f esté entrenada, esta tendrá un comportamiento similar a la función desconocida fpdata (i.e., f≈fpdata en algún sentido preciso).
En general, una red neuronal está formada por la composición de K∈N funciones individuales, fk:RDk−1→RDk (con D0=D y DK=C), es decir:
f(x)=fK(fK−1(…(f1(x))…))
Las funciones fk:RDk−1→RDk suelen estar definidas por expresiones matemáticas simples (e.g., transformaciones afines) y suelen llamarse bloques o capas, por lo que al entero K>1 se le llama número de capas de la red neuronal. Cada capa fk tiene asociado un conjunto de parámetrosθk que definen el comportamiento de la función, y que van cambiando durante el entrenamiento de la red neuronal. Sin pérdida de generalidad, siempre se asumirá que los parámetros de cada capa fk son vectores en RPk. De esta forma, se dice que la red neuronal tiene P=∑k=1KPk parámetros. Más aún, concatenando los K parámetros en un único vector, se puede considerar que θ=θ1θ2⋮θK∈RP es el vector de parámetros de la red neuronal, lo que motiva a utilizar la notación fθ para indicar una red neuronal con (vector de) parámetros θ.
A lo largo del libro, las redes neuronales serán, por lo general, usadas para ajustar los parámetros de una distribución de probabilidad p(x) (notar el alcance de nombre entre los parámetros de la red neuronal y los parámetros de la distribución). Por ejemplo, si pdata(x)∼N(μdata,Σdata) es una variable aleatoria gaussiana con parámetros μdata y Σdata desconocidos, se podrían usar dos redes neuronales, μθ y Σθ, para estimar estos parámetros. Para esto será suficiente contar con un conjunto de entrenamiento D={x1,…,xN} compuesto por muestras generadas a partir de la distribución pdata(x). De esta forma, si la red queda bien entrenada, la distribución pθ(x)∼N(μθ,Σθ) sería una buena aproximación de la distribución desconocida pdata(x).
Entrenamiento
Entrenar una red neuronal fθ:RD→RC usando un conjunto de entrenamiento D={(x1,y1),…,(xN,yN)}⊂RD×RC significa adaptar sus parámetros, θ∈RP, de tal forma que fθ(xn)≈yn, para todo n∈{1,…,N}. Este proceso se llama (pre-)entrenamiento y, para los grandes modelos actuales, suele requerir una gran cantidad de datos de entrenamiento.
Para realizar el entrenamiento es necesario elegir una función de pérdida L:RC×RC→R que mida la discrepancia entre el valor real, y∈RC, y el predicho por la red neuronal, y^∈RC (e.g., L(y^,y)=∥y−y^∥2) para una entrada x∈RD cualquiera. Con esto, para cada par (xn,yn)∈D, se compara la salida de la red neuronal, y^n=fθ(xn), con el valor real, yn. Promediando (o sumando) las pérdidas individuales se puede obtener el valor de la función de pérdida total:
LD(θ)=N1n=1∑NL(fθ(xn),yn)
Con esta función definida, se pueden ajustar los parámetros de la red neuronal de tal forma que minimicen el valor de LD(θ). Para esto, lo más usual es usar algoritmos de gradiente, donde el más simple de estos algoritmos es descenso del gradiente, el cual comienza con un vector de parámetros θ∈RP aleatorio y luego realiza iteraciones de la forma
θ←θ−γ∇θLD(θ)
La constante γ>0 se llama tasa de aprendizaje y define a qué velocidad se actualizan los parámetros durante el entrenamiento (también es posible considerar una tasa de aprendizaje individual para cada parámetro). De manera intuitiva, el algoritmo de descenso del gradiente cumple su función de minimizar LD(θ) debido a que el gradiente ∇θLD(θ)∈RP apunta en la dirección de máximo crecimiento de LD(θ)∈R, por lo que −∇θLD(θ) apunta en la dirección de máximo decrecimiento. Con esto, si γ>0, entonces θ−γ∇θLD(θ) es un nuevo vector de parámetros que entrega un menor valor para la función de pérdida LD.
Otros optimizadores (e.g., Adam [27] o Prodigy [28]) cambian la expresión matemática de las iteraciones, pero siempre necesitan conocer el gradiente ∇θLD(θ), el cual es computado utilizando la regla de la cadena (de la derivada) sobre la red neuronal fθ(x)=fK(fK−1(…(f1(x))…)). La forma usual de realizar este cálculo en cadena es mediante un algoritmo de programación dinámica llamado backpropagation, el cual viene implementado en todas las librerías de Python enfocadas en redes neuronales y diferenciación automática (e.g., PyTorch, TensorFlow o JAX).
Redes fully connected
Dependiendo del tipo de capa neuronal fk:RDk−1→RDk que se utilice, la red neuronal recibe diferentes nombres. Por ejemplo, si todas las capas son de la forma fk(x)=Φ(Akx+bk) (con Φ una función no lineal), entonces la red se dice fully connected, mientras que si en vez de transformaciones afines generales se utilizan convoluciones, la red se dice convolucional.
Para ejemplos simples, la red fully connected es más que suficiente, por lo que suele ser el tipo de red neuronal que se usa como baseline, mientras que para trabajar con imágenes, donde D=ancho×alto×n° canales, las redes convolucionales funcionan mejor. Por otro lado, para trabajar con secuencias de texto o de otro tipo, se suele utilizar otro tipo de arquitectura, como las arquitecturas recurrentes (e.g., GRU [29]). Sin embargo, hoy en día, las arquitecturas recurrentes han sido sustituidas por la arquitectura Transformer [14], la cual puede considerarse como uno de los trabajos más importantes en el deep learning moderno (aunque el paper original no sirve para predecir todo el potencial que tuvo a futuro).
El tipo de red neuronal más simple es la red fully connected (FC), también llamada multilayer perceptron (MLP). En este tipo de red neuronal cada bloque fk:RDk−1→RDk es de la forma
fk(x)=Φ(Akx+bk),
donde la matriz de pesosAk∈MDk,Dk−1(R) y el vector de sesgosbk∈RDk son los parámetros de la capa lineal fk (cada capa tiene Dk×Dk−1+Dk parámetros). La función Φ:RDk→RDk suele ser una misma función escalar (no lineal) que se aplica en cada una de las coordenadas del vector de pre-activación, y^k=Akx+bk∈RDk, es decir: Φ(y)=(ϕ(y1),…,ϕ(yDk)), donde ϕ:R→R es una función no lineal fija que se aplica en cada coordenada de y∈RDk, llamada función de activación.
Las dimensiones intermedias, D1,…,DK−1, pueden ser todas iguales, decrecer y luego volver a crecer (como en un autoencoder) o seguir otro tipo de patrón. Por otro lado, en muchos modelos, el vector de sesgo bk∈RDk se suele omitir (haciendo esto, la GPU puede realizar los cálculos más eficientemente), mientras que la matriz de pesos Ak∈MDk,Dk−1(R) se suele inicializar con un valor cercano a cero, donde la inicialización de Xavier [30] y la inicialización de He [31] son las más usadas.
Una forma natural de motivar este tipo de redes neuronales es pensar en el problema de encontrar el patrón más simple posible (basándose en el principio de parsimonia) que se pueda repetir varias veces para lograr ajustar cualquier función. Se puede demostrar que la función más simple que cumple este requisito es la función afín f(x)=Ax+b. Más precisamente, se puede demostrar que este tipo de redes neuronales puede aproximar (en el sentido de la convergencia uniforme sobre compactos) a cualquier función continua f:RD→RC si es que no se pone límite en el número de parámetros. Este tipo de resultados se conocen como teoremas de aproximación universal, y hoy en día se conocen muchas extensiones y mejoras al resultado mencionado.
Es importante destacar que este tipo de red neuronal se puede extender fácilmente a más entradas, lo cual será útil al estudiar modelos generativos condicionales, donde las entradas adicionales son interpretadas como información adicional para la generación (e.g., un prompt para un modelo que genera imágenes o una imagen para tareas de transferencia de estilo). La forma usual de insertar información adicional a una red neuronal es inyectándola directamente en cada uno de los bloques de la red. Así, si la información adicional es un vector c∈RJ, cada bloque fk:RDk−1→RDk se puede sustituir por otro bloque fk:RDk−1×RJ→RDk que ahora también procese la entrada adicional c. En el caso de una red fully connected, este capítulo adicional puede ser inyectada de la misma forma que se procesa la entrada original, x∈RDk−1, añadiendo una matriz adicional de parámetros:
fk(x,c)=Φ(Akx+Bkc+dk),
donde Ak∈MDk,Dk−1(R), Bk∈MDk,J(R) y dk∈RDk son los parámetros del bloque fk.
Es importante notar que esta forma de calcular fk(x,c) es equivalente a concatenar los vectores de entrada, x∈RDk−1 y c∈RJ, y trabajar con un único vector extendido x=(xc)∈RDk−1+J definiendo fk(x)=Φ(Akx+dk), donde Ak=(Ak∣Bk)∈MDk,Dk−1+J(R) es la concatenación horizontal de las matrices Ak y Bk. Esta observación es importante ya que es usual encontrarse con ambos tipos de implementaciones, por lo que es importante reconocer que son equivalentes.
Clasificación con redes neuronales
En esta sección se implementará, a modo de ejemplo, una red neuronal para resolver el problema de clasificación utilizando un dataset de entrenamiento D={(x1,y1),…,(xN,yN)} compuesto por imágenes x∈RD y etiquetas de clase y∈{M1,…,MC} (e.g., y=Mc indica que la imagen x pertenece a la clase número c dentro de un conjunto de C clases). Para formular este problema usando redes neuronales, es usual considerar que la etiqueta de cada muestra x∈RD fue generada a partir de una distribución condicional desconocida, pdata(y∣x). Notar que la variable aleatoria y (condicional a una imagen x) es discreta ya que supp(y)={M1,…,MC}, por lo que se puede considerar, sin pérdida de generalidad, que pdata(y∣x)∼Categoˊrica(rdata), donde rdata∈C es un vector de probabilidad desconocido.
Dado que el objetivo del problema de clasificación es predecir a qué clase y∈{M1,…,MC} pertenece una imagen x∈RD dada, es suficiente entrenar una red neuronal rθ:RD→[0,1]C que defina el vector de probabilidades de un modelo pθ(y∣x)∼Categoˊrica(rθ(x)) utilizando el conjunto de entrenamiento D. Este tipo de modelos, llamados modelos discriminativos, utiliza un tipo de aprendizaje conocido como aprendizaje supervisado, donde cada muestra del dataset, x∈RD, tiene asociada una etiqueta, y∈{M1,…,MC}.
Es importante notar que para cualquier imagen de entrada x∈RD, la salida de la red neuronal, rθ(x), debe ser un vector de probabilidad (i.e., rθ(x)c≥0 para todo c∈{1,…,C} y ∑c=1Crθ(x)c=1), lo cual no necesariamente ocurre en la salida de una red neuronal, por ejemplo, fully connected. Para solucionar esto, es usual aplicar la función softmax a la salida de la red neuronal, la cual transforma todas las coordenadas en positivas (utilizando la función exponencial) y luego fuerza a que sumen 1 dividiendo cada coordenada por la suma de todo el vector. Más precisamente, para un vector r∈RC cualquiera, se define softmax:RC→C como
softmax(s):=(∑c=1Cesces1,…,∑c=1CescesC)
donde es directo ver que softmax(s)c∈[0,1] para todo c∈{1,…,C} y que ∑c=1Csoftmax(s)c=1, por lo que efectivamente r=softmax(s)∈C.
Para implementar y entrenar una red neuronal para el problema de clasificación de imágenes se utilizarán las siguientes librerías:
import randomimport matplotlib.pyplot as pltimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoaderfrom torchvision import datasets, transformsfrom torchsummary import summary
El objetivo será entrenar un clasificador para el dataset Fashion MNIST [32], el cual consiste en imágenes de C=10 tipos diferentes de prendas de vestir:
Las etiquetas dentro de las muestras por lo general están asignadas con números enteros (del 0 al 9 en este caso), por lo que el nombre real de las clases deben ser obtenidos desde la lista labels. Por otro lado, la transformación transforms.ToTensor() es aplicada a cada elemento x del dataset y su objetivo es transformar una imagen (objeto tipo PIL.Image.Image) en un objeto tipo torch.Tensor, el cual puede verse como la versión PyTorch de los np.ndarray de NumPy (la principal diferencia es que los tensores de PyTorch pueden rastrear el grafo computacional para el cálculo de los gradientes usados durante el entrenamiento). Además, la transformación transforms.ToTensor() escala linealmente todos los pixeles de x al intervalo [0,1].
Para acceder a una muestra del dataset, basta con recorrer sus índices:
x | Tipo: <class ‘torch.Tensor’> - dimensiones: torch.Size([1, 28, 28]) y | Tipo: <class ‘int’> - valor: 9
Notar que PyTorch coloca la dimensión de los canales al comienzo del tensor x, por lo que es necesario permutar esa dimensión para poder visualizar la imagen con matplotlib (que espera la dimensión de los canales al final).
Para el entrenamiento de la red neuronal, es usual usar sub-conjuntos del dataset de entrenamiento D (llamados batches) en vez de todo el conjunto en cada actualización de parámetros. Esta variante del algoritmo del descenso del gradiente se conoce como descenso del gradiente estocástico (SGD) y por lo general permite entrenamientos más eficientes. En PyTorch, la clase que genera los batches de entrenamiento se llama DataLoader:
Notar que el dataloader retorna un batch de muestras y un batch de etiquetas. En ambos casos, la dimensión del batch siempre es la primera dimensión ya que las redes neuronales de PyTorch (casi) siempre esperan entradas con ese formato.
Como red neuronal se utilizará una red fully connected de 2 capas, donde la dimensión interna (valor D1) será indicada por el parámetro hidden_dim:
class MLP(nn.Module):def__init__(self, input_dim: int, output_dim: int, hidden_dim: int) ->None:super().__init__()self.fc1 = nn.Linear(in_features=input_dim, out_features=hidden_dim)self.fc2 = nn.Linear(in_features=hidden_dim, out_features=output_dim)def forward(self, x: torch.Tensor) -> torch.Tensor: x = nn.Flatten()(x) x = nn.ReLU()(self.fc1(x)) x = nn.Softmax(dim=-1)(self.fc2(x))return x
Notar que la cantidad de parámetros es consistente: la primera capa lineal tiene 4×784+4=3140 parámetros (donde 784=1×28×28), mientras que la segunda capa tiene 10×4+10=50 parámetros. Además, considerando que cada parámetro ocupa 32 bits de memoria (precisión por defecto en PyTorch), se necesitan 3190×832=12760 bytes (≈12 kilobytes o 0.012 megabytes) de memoria para almacenar el valor de sus parámetros. Sin embargo, la cantidad de memoria para almacenar un modelo moderno puede escalar hasta los cientos de gigabytes (e.g., LLaMA 3.1-405B requiere 1620 gigabytes en precisión completa), mientras que la cantidad de memoria necesaria (en GPU) para entrenar un modelo puede ser varias veces la memoria necesaria para solo hacer inferencia debido a que durante el entrenamiento también es necesario almacenar otros tensores asociados al cálculo de gradientes y a valores temporales del optimizador.
La función de pérdida que se utilizará será la entropía cruzada [33], la cual es una función que permite comparar dos distribuciones de probabilidad (en este caso, pθ(y∣x) y pdata(y∣x)). Esta función de pérdida será estudiada más en detalle cuando se implemente un modelo autorregresivo ya que es la función de pérdida estándar para entrenar modelos de lenguaje.
A cada iteración completa que se le de al dataset de entrenamiento D se le suele llamar época, y la cantidad de épocas que se entrena cada modelo depende siempre del tipo de datos y el tamaño del modelo. En este caso, será suficiente con entrenar el modelo una época. Además, el entrenamiento se puede realizar en CPU o en GPU, donde la segunda opción siempre es la preferida para grandes modelos debido a que acelera considerablemente el entrenamiento. Para esto se define la variable DEVICE que se fija como cuda (GPU de Nvidia) cuando sea posible.
El loop de entrenamiento es el siguiente:
DEVICE = torch.device('cuda'if torch.cuda.is_available() else'cpu')def train(net: nn.Module, optimizer: optim.Optimizer, dataloader: DataLoader, epochs: int) ->None: net.to(DEVICE) net.train() loss_fn = nn.CrossEntropyLoss()for epoch inrange(epochs):for x, y in dataloader: x, y = x.to(DEVICE), y.to(DEVICE) output = net(x) loss = loss_fn(output, y) optimizer.zero_grad() loss.backward() optimizer.step()
Como optimizador se elegirá Adam [34] ya que suele ser el optimizador usado por defecto. Para instanciarlo es necesario indicarle los parámetros que debe ir actualizando en cada iteración:
Una vez el modelo está entrenado es posible utilizarlo para predecir la clase de una nueva imagen. Para esto, basta pasar la imagen por la red neuronal y elegir la clase con mayor probabilidad (aunque también se podría elegir aleatoriamente la clase de acuerdo a la distribución pθ(y∣x) que entrega la red neuronal). La siguiente función make_prediction recibe una lista de imágenes y predice a qué clase pertenecen para así comparar la predicción con la clase real:
Es importante mencionar que hacer inferencia utilizando imágenes desde el conjunto de entrenamiento no permite evaluar el overfitting del modelo. Sin embargo, se utilizará este mismo dataset por simplicidad. Para hacer inferencia, basta llamar a la función implementada:
indices = random.sample(range(len(dataset)), 10)images = [dataset[i][0] for i in indices]true_labels = [dataset[i][1] for i in indices]make_prediction(mlp, images, true_labels)
Se observa que la red neuronal fue capaz de aprender a clasificar las imágenes, con un cierto grado de error. Aumentando la cantidad de neuronas en hidden_dim se puede mejorar más esta precisión.
Es importante no olvidar que la salida de la red neuronal, rθ(x)∈[0,1]10, es el vector de probabilidades de una distribución pθ(y∣x) sobre las clases y no únicamente una predicción de a qué clase pertenece x (aunque, en este caso, se realizó la predicción eligiendo la clase con mayor probabilidad). Esto es importante ya que en algunos modelos generativos, como los usados para la generación de texto, elegir siempre la clase con mayor probabilidad no suele ser la mejor opción.
Por otro lado, dado que se está trabajando con imágenes, resultaría más conveniente utilizar una red convolucional para procesar la entrada. Este tipo de redes neuronales será recordada al estudiar arquitecturas neuronales para GANs.
En la próximo capítulo se comenzará el estudio de las redes bayesianas, las cuales son el marco teórico general sobre el cual se pueden formular (casi) todos los modelos generativos estudiados a lo largo del libro.
Sutskever, Ilya, Vinyals, Oriol, Le, Quoc V., “Sequence to Sequence Learning with Neural Networks”, Advances in Neural Information Processing Systems (NeurIPS), 2014. https://arxiv.org/abs/1409.3215
Rombach, Robin, Blattmann, Andreas, Lorenz, Dominik, Esser, Patrick, Ommer, Björn, “High-Resolution Image Synthesis with Latent Diffusion Models”, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. https://arxiv.org/abs/2112.10752
Zhu, Jun-Yan, Park, Taesung, Isola, Phillip, Efros, Alexei A., “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”, IEEE International Conference on Computer Vision (ICCV), 2017. https://arxiv.org/abs/1703.10593
Polyak, Adam, others, “Movie Gen: A Cast of Media Foundation Models”, arXiv preprint arXiv:2410.13720, 2024. https://arxiv.org/abs/2410.13720
Lipman, Yaron, Chen, Ricky T. Q., Ben-Hamu, Heli, Nickel, Maximilian, Le, Matt, “Flow Matching for Generative Modeling”, International Conference on Learning Representations (ICLR), 2023. https://arxiv.org/abs/2210.02747
Liu, Xingchao, Gong, Chengyue, Liu, Qiang, “Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow”, International Conference on Learning Representations (ICLR), 2023. https://arxiv.org/abs/2209.03003
Black Forest Labs, “FLUX.1 Kontext: Flow Matching for In-Context Image Generation”, arXiv preprint arXiv:2506.15742, 2025. https://arxiv.org/abs/2506.15742
Goodfellow, Ian J., Pouget-Abadie, Jean, Mirza, Mehdi, Xu, Bing, Warde-Farley, David, Ozair, Sherjil, Courville, Aaron, Bengio, Yoshua, “Generative Adversarial Nets”, Advances in Neural Information Processing Systems (NeurIPS), 2014. https://arxiv.org/abs/1406.2661
Srivastava, Nitish, Hinton, Geoffrey, Krizhevsky, Alex, Sutskever, Ilya, Salakhutdinov, Ruslan, “Dropout: A Simple Way to Prevent Neural Networks from Overfitting”, Journal of Machine Learning Research, 2014. https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf
Kingma, Diederik P., Ba, Jimmy, “Adam: A Method for Stochastic Optimization”, International Conference on Learning Representations (ICLR), 2015. https://arxiv.org/abs/1412.6980
Glorot, Xavier, Bengio, Yoshua, “Understanding the difficulty of training deep feedforward neural networks”, International Conference on Artificial Intelligence and Statistics (AISTATS), 2010. https://proceedings.mlr.press/v9/glorot10a
He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing, Sun, Jian, “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification”, IEEE International Conference on Computer Vision (ICCV), 2015. https://arxiv.org/abs/1502.01852