
Redes bayesianas (mixturas, Naïve Bayes, cadenas de Markov, HMMs) como lenguaje común para los paradigmas generativos. Modelos condicionales, variable latente, estimación MAP y máxima verosimilitud.
Dada la diversidad de paradigmas y la modularidad de los modelos actuales, resulta útil realizar el estudio bajo la perspectiva unificada de los modelos gráficos probabilísticos, lo que permite obtener un entendimiento más holístico de la IA generativa moderna y entender más fácilmente las similitudes y diferencias que hay entre los distintos paradigmas generativos. Por otro lado, este enfoque es natural dado que todos los modelos generativos modernos suelen ser formulados y analizados en términos probabilísticos. Más aún, todos los paradigmas que se estudiarán (a excepción de los modelos basados en score) pueden ser vistos como un tipo particular de modelo gráfico denominado red bayesiana. En consecuencia, este capítulo comienza estudiando algunos aspectos importantes de este marco teórico, para luego revisar el problema de inferencia en redes bayesianas, el cual puede interpretarse como el proceso de entrenamiento en la jerga usual del machine learning.
Introducción a las redes bayesianas
Un modelo gráfico consiste, a grandes rasgos, en poder representar las relaciones de dependencia e independencia entre las variables de un modelo probabilístico utilizando un grafo. Esta representación visual permite entender rápidamente cómo están relacionadas las variables, ya sean visibles u ocultas, dentro de un modelo probabilístico complejo como, por ejemplo, en un modelo de Markov oculto usado para la tarea part-of-speech tagging en texto.
Dado un modelo probabilístico con distribución conjunta , el modelo gráfico asociado a este modelo probabilístico es un grafo cuyos nodos representan las variables aleatorias del modelo (hay un nodo por cada variable), mientras que la existencia de un arco entre dos nodos indica que hay una relación de dependencia (en el sentido probabilístico) entre las variables aleatorias asociadas a esos nodos.
Los modelos gráficos se pueden clasificar en dos grandes grupos, dependiendo del tipo de grafo que utilicen para representar al modelo probabilístico:
Red bayesiana o belief networks: en este caso, se utiliza un grafo dirigido (i.e., cada arco tiene una dirección) para representar la relación de dependencia entre variables. En este tipo de modelos, un arco dirigido desde (el nodo) hacia (el nodo) indica que hay una relación de dependencia entre (la variable) y (la variable) . Se verá que el grafo dirigido asociado a un modelo probabilístico siempre debe ser acíclico para que esta interpretación tenga sentido.
Redes de Markov o Markov random fields (MRF): en este tipo de modelos se utiliza un grafo no dirigido (i.e., no se diferencia entre un nodo origen y un nodo destino), por lo que ya no hay una jerarquía en las relaciones de dependencia. En consecuencia, la factorización de la distribución conjunta para este tipo de modelos se vuelve un poco diferente ya que se debe realizar sobre los cliques maximales del grafo, mientras que los términos que se multiplican ya no se interpretan como distribuciones, si no que se interpretan como potenciales. Este tipo de modelos no es muy importante para la IA generativa moderna, por lo que solo se comentará brevemente al estudiar los modelos basados en energía. Es importante mencionar que varios modelos generativos clásicos como las máquinas de Boltzmann o las redes de Hopfield (Nobel de física, 2024) son modelos de este tipo.
Ejemplo inicial
Para introducir la idea de red bayesiana, se comenzará con un ejemplo que modela la probabilidad de aprobar o no un curso, considerando únicamente si un estudiante estudia o no para el examen, y su rendimiento en las preguntas el examen. Para esto, se considerarán 4 variables aleatorias binarias (i.e., Bernoulli), , , y , las cuales representarán los siguientes escenarios:
Variable aleatoria : el estudiante estudia para el examen.
Variable aleatoria : el estudiante responde bien las preguntas teóricas.
Variable aleatoria : el estudiante responde bien las preguntas prácticas.
Variable aleatoria : el estudiante aprueba el curso.
Como es usual, se asociará la respuesta “sí” al valor y la respuesta “no” al valor . El siguiente grafo dirigido representa la relación entre las 4 variables aleatorias que considera el modelo:
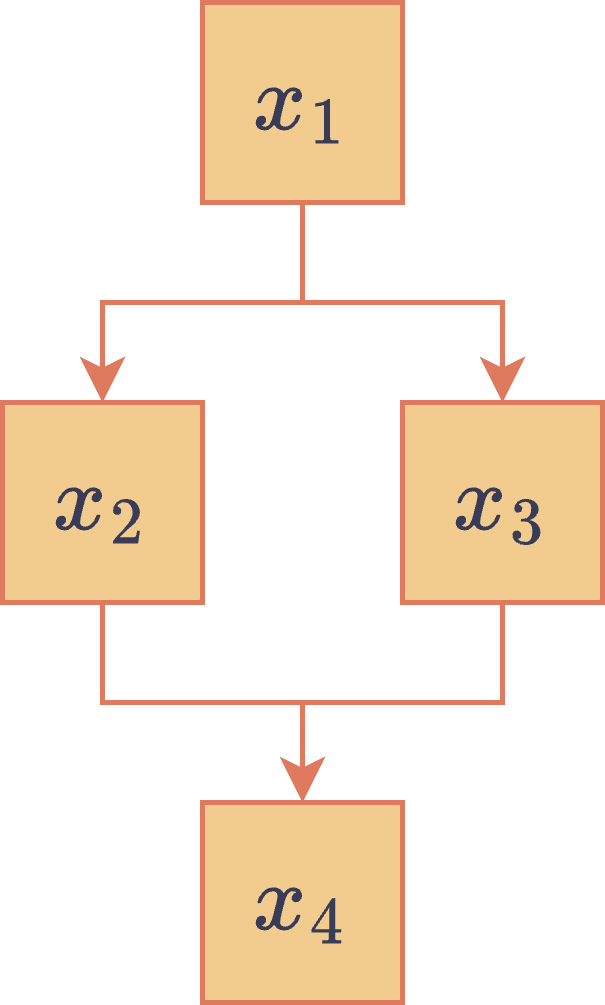
Red bayesiana del ejemplo del estudiante.
Este grafo indica que las variables aleatorias y dependen de , mientras que la variable aleatoria depende de las variables aleatorias y . Más precisamente, este grafo se interpreta factorizando la distribución conjunta de las 4 variables aleatorias como
Es útil notar algunas independencias condicionales que induce esta factorización:
La variable aleatoria es condicionalmente independiente, dado el valor de , de la variable aleatoria : o, equivalentemente, . Esta independencia indica que responder bien o no en las preguntas prácticas es independiente de responder bien o no en las preguntas teóricas, si es que se sabe si el estudiante estudió o no.
La variable aleatoria es condicionalmente independiente de la variable aleatoria , dados los valores de y : o, equivalentemente, . Esta independencia indica que aprobar o no el examen no depende de si el estudiante estudió o no, si es que se sabe si respondió bien o no las preguntas teóricas y las preguntas prácticas.
Estas independencias condicionales se observan en la simplificación de la factorización de la distribución conjunta que se obtiene cuando se factoriza usando la regla de la cadena (la cual no asume ninguna independencia, solo utiliza la definición de probabilidad condicional):
Notar que para definir cada una de las distribuciones condicionales, es necesario definir una distribución para cada posible valor de las variables condicionales. Por ejemplo, la distribución necesitaría definir distribuciones binarias sobre (una para cada posible valor de ), mientras que necesita definir solo distribuciones binarias sobre . Esto muestra cómo las hipótesis de independencia ayudan a reducir la cantidad de parámetros necesarios para definir una distribución conjunta.
Si se conocen todas las distribuciones de la factorización, es directo responder preguntas como ¿cuál es la probabilidad de responder bien las preguntas teóricas si se estudió? o ¿cuál es la probabilidad de aprobar el curso si respondió bien las preguntas prácticas y teóricas? ya que bastaría con mirar los parámetros de las distribuciones. Sin embargo, otras preguntas requieren hacer cálculos adicionales como marginalización o cálculo de posteriores. Algunas preguntas de este tipo son:
¿Cuál es la probabilidad de que el estudiante responda bien las preguntas teóricas?
¿Cuál es la probabilidad de que el estudiante haya estudiado si no respondió bien las preguntas teóricas?
¿Cuál es la probabilidad de responder bien tanto las preguntas teóricas como las preguntas prácticas?
¿Cuál es la probabilidad de responder bien las preguntas prácticas si se respondieron bien las preguntas teóricas?
Para responder las preguntas se asignarán probabilidades de juguete a cada una de las distribuciones que definen la probabilidad conjunta . Notar que la suma de las probabilidades de cada fila debe ser para representar una distribución de probabilidad válida.
¿Cuál es la probabilidad de que el estudiante responda bien las preguntas teóricas?
Se debe calcular . Esto se puede hacer marginalizando la distribución conjunta:
Es decir, sin observar ninguna variable a priori (e.g., sin saber si el estudiante estudió o no), es cerca de un probable que el estudiante responda bien las preguntas teóricas. Notar que para pasar a la cuarta igualdad se utilizó que para la distribución y luego para la distribución .
¿Cuál es la probabilidad de que el estudiante haya estudiado si no respondió bien las preguntas teóricas?
Se debe calcular . Para esto, se puede usar la definición de probabilidad condicional y luego marginalizar la distribución conjunta:
En la penúltima igualdad se usó el resultado de la pregunta anterior para obtener .
Por otro lado, notar que esta distribución condicional no está en la factorización entregada por el grafo y, de hecho, tiene la dirección contraria al orden que induce el grafo. Por lo tanto, también se podría calcular esta probabilidad posterior utilizando la regla de Bayes:
Llegando a la misma expresión que antes.
¿Cuál es la probabilidad de responder bien tanto las preguntas teóricas como las preguntas prácticas?
Se debe calcular . Esto se puede hacer, al igual que antes, marginalizando la distribución conjunta:
Notar que ya que y solo son independientes cuando se conoce el valor de (i.e., son condicionalmente independientes).
¿Cuál es la probabilidad de responder bien las preguntas prácticas si se respondieron bien las preguntas teóricas?
Se debe calcular . Notar que ya que, como se mencionó anteriormente, y solo son independientes cuando se conoce el valor de . La cantidad buscada se puede obtener por definición de probabilidad condicional:
Donde se usaron los resultados de las preguntas anteriores.
Los desarrollos anteriores muestran que siempre se puede seguir el mismo procedimiento de marginalización para obtener alguna probabilidad deseada. Sin embargo, en muchos casos estos cálculos de pueden hacer de manera más eficiente utilizando la regla de Bayes cuando se busca conocer una distribución posterior.
Por otra parte, desde la perspectiva del grafo asociado al modelo probabilístico, sus nodos son , mientras que sus arcos son . Además, no tiene nodos padres, y tienen a como único nodo padre, y tiene a y a como nodos padres.
Notar que la estructura del grafo anterior puede ser usada para representar otros escenarios con una dinámica similar: una primera variable influye en el valor de otras dos variables condicionalmente independientes, las cuales a su vez influyen en una cuarta variable. Por otro lado, en este ejemplo se conocen las distribuciones de cada nodo (cada variable aleatoria sigue una distribución Bernoulli, cuyos parámetros se pueden deducir de las tablas), lo que permitió responder preguntas (i.e., hacer inferencia bayesiana) acerca del modelo. En los modelos generativos modernos no se conoce a priori la distribución de los datos (e.g., texto o imágenes), por lo que esta suele ser aprendida por una red neuronal utilizando muestras de entrenamiento generadas desde la distribución desconocida. Una vez se tiene el modelo probabilístico entrenado, se pueden generar nuevas muestras a partir de él, las cuales serán similares a las muestras usadas durante el entrenamiento ya que el modelo habrá aprendido a replicar la distribución original de los datos, la cual, en un comienzo, era desconocida. De esta forma, es posible utilizar redes neuronales para generar texto, imágenes u otro tipo de dato.
Formulación de una red bayesiana
Para dar una definición más precisa de lo que es una red bayesiana, es importante recordar que toda la información acerca de cómo se relacionan las distintas variables aleatorias dentro de un modelo probabilístico está contenida en su distribución conjunta , la cual es más informativa que el conjunto de marginales ya que las marginales pierden las relaciones entre las variables. Sin embargo, muchas veces los modelos suelen incluir hipótesis de independencia entre ellas para regularizar el modelo haciéndolo más simple, lo que en particular ayuda a evitar el overfitting (un modelo más débil no puede gastar capacidad en memorizar muestras de entrenamiento). Por otro lado, las hipótesis de independencia permiten disminuir la cantidad de parámetros necesarios para definir la distribución conjunta . A modo de ejemplo, si las variables son binarias, la cantidad de combinaciones distintas entre ellas es , por lo que la distribución conjunta necesitaría una cantidad exponencial (en el número de variables) de valores para poder ser definida completamente. Con hipótesis de independencia, este costo exponencial puede ser disminuido significativamente, llegando incluso a un costo lineal en el caso extremo donde todas las variables se asumen independientes entre sí (como ocurre en los unigramas de texto). Para formular las hipótesis de independencia, es necesario recordar algunos conceptos elementales de teoría de grafo.
Un grafo dirigido es una estructura matemática compuesta por un conjunto de nodos y por un conjunto de arcos . Cada arco del grafo se representa como una flecha que va de un nodo a otro. Matemáticamente, un arco se suele denotar como un par ordenado de nodos, es decir, la afirmación indica que el grafo posee un arco dirigido desde el nodo hacia el nodo . En particular, esta notación indica que . Las siguientes definiciones son importantes para formalizar el concepto de red bayesiana:
Camino dirigido: una secuencia de vértices se dice que es un camino dirigido desde hasta si al recorrer los vértices de la secuencia (en el orden dado por la secuencia) se sigue el orden dado por los arcos, es decir, para todo .
Grafo dirigido acíclico (DAG): un grafo dirigido se dice acíclico si para todo nodo , no es posible encontrar un camino dirigido que empiece y termine en . Es decir, no se pueden formar caminos dirigidos cerrados (este tipo de caminos se llama ciclo).
Nodos padres: los DAG inducen una jerarquía sobre el conjunto de los nodos del grafo. Para un nodo , sus nodos padres son los nodos que están directamente conectados a él, es decir, .
Orden topológico: los DAG inducen un orden (parcial) sobre a partir de la jerarquía impuesta por la orientación de los arcos. Este orden se denomina orden topológico y siempre se asumirá, sin pérdida de generalidad, que los vértices de un DAG están enumerados de acuerdo al orden topológico del grafo, es decir, , donde es la cantidad de nodos, y si .
Dado un conjunto de variables aleatorias, , la idea general de una red bayesiana es poder representar la factorización de su distribución conjunta como un DAG , donde sus nodos son las variables aleatorias del modelo probabilístico (i.e., ), mientras que la presencia de un arco dirigido desde el nodo hacia el nodo indica que la variable influye directamente en el valor de la variable (o que depende directamente de ). Más precisamente, la noción de independencia que induce un DAG, denominada propiedad de Markov, es , donde . Esta noción de independencia indica que , es decir, todo nodo es independiente de sus ancestros (nodos hacia arriba en la jerarquía) si se conoce el valor de sus nodos padres. De esta forma, sustituyendo las propiedades de independencia en la factorización que entrega la regla de la cadena, , la distribución conjunta del modelo probabilístico asociado al DAG se factoriza como
Notar que los nodos raíces del grafo (nodos donde ) definen probabilidades incondicionales , por lo que (las distribuciones de) estas variables se suelen llamar priors, mientras que las variables donde interactúan de forma condicional con sus nodos padres, permitiendo muchas veces obtener un modelo intuitivo e interpretable. Por otro lado, entendiendo como que causa (en un sentido informal), no tendría sentido que también (i.e., que cause ). Esta observación permite entender por qué se necesita que el grafo sea acíclico para poder ser interpretado como una red bayesiana.
En el caso de trabajar únicamente con variables discretas (e.g., categóricas), los parámetros de las distribuciones condicionales se pueden almacenar en tablas de forma similar a las tablas construidas en el ejercicio inicial. Sin embargo, los modelos generativos modernos requieren aprender distribuciones mucho más complejas, usualmente continuas, por lo que se suele utilizar redes neuronales que se sabe que funcionan bien en tareas que requieren capturar patrones en alta dimensión. Por lo general, cada factor de una red bayesiana suele seguir una distribución típica, donde sus parámetros (de la distribución, no de la red neuronal) son aprendidos por una red neuronal cuya entrada son los valores de las variables condicionantes (i.e., los valores de las variables en ), mientras que la salida son los parámetros que requiere la distribución para quedar totalmente definida. A modo de ejemplo:
Si es una imagen (monocromática), donde , y es el -ésimo pixel de la imagen (cuyo valor es 0 o 1 por simplicidad), entonces cada pixel puede ser considerado como una distribución Bernoulli, , donde es el parámetro de la distribución, cuyo valor depende de los pixeles en . Este parámetro suele ser determinado por una red neuronal (con salida sigmoidal para estar en el intervalo ), cuya entrada son los valores de los pixeles vecinos que el modelo considere. Por ejemplo, una capa convolucional considera como únicamente a los pixeles que están dentro del campo receptivo de la convolución.
Si es una variable continua (y cada componente es un escalar irrestricto), es usual considerar , donde los parámetros y dependen de los valores de las variables en . Al igual que antes, estos parámetros suelen estar determinados por redes neuronales cuyas entradas son los valores de las variables en .
Notar que en todos los ejemplos se ha considerado que cada es una variable aleatoria unidimensional. En general, cada variable por sí sola puede ser un vector aleatorio de varias dimensiones, por lo que no se diferenciará, como es usual en machine learning, entre variable aleatoria y vector aleatorio. Más aún, cada nodo puede estar representando a un conjunto de variables aleatorias que, por sus propiedades de independencia, pueden agruparse en un mismo nodo.
Por otro lado, es importante mencionar que las redes bayesianas no se llaman así debido a que asumen la interpretación bayesiana. El nombre se debe a que utilizan la regla de Bayes para hacer inferencia sobre las variables desconocidas.
Generación de muestras
Dada una red bayesiana , donde las distribuciones son todas conocidas (y con parámetros conocidos o aprendidos con una red neuronal), entonces el algoritmo de ancestral sampling permite generar una nueva muestra desde la distribución conjunta . Si bien esto no siempre es necesario (e.g., en el ejemplo inicial no es claro para qué sería útil generar muestras a partir de esa red bayesiana), en IA generativa el sampling es la tarea más importante luego del entrenamiento ya que permite, por ejemplo, generar nuevas respuestas si se tiene un LLM ya entrenado o generar una nueva imagen si se tiene un modelo de difusión ya entrenado.
El algoritmo de ancestral sampling comienza, naturalmente, generando muestras desde los nodos raíces (que funcionan como semillas) y luego utiliza estas muestras para generar nuevas muestras de los nodos hijos. Este procedimiento se repite jerárquicamente (i.e., con el orden de generación siguiendo el orden topológico del grafo) hasta llegar al último nodo, obteniendo así una muestra desde todos los nodos del grafo. La muestra conjunta resultante de este procedimiento, , es una muestra generada desde la distribución conjunta .
Es importante destacar que el algoritmo de ancestral sampling asume que se sabe cómo generar nuevas muestras desde cada factor de la red bayesiana. Este es otro motivo por el cual los modelos gráficos suelen elegir distribuciones condicionales simples (e.g., categóricas o gaussianas) en sus formulaciones.
En los paradigmas generativos que se revisarán, el sampling será realizado casi siempre usando ancestral sampling: en modelos de variable latente como las GANs o los VAEs, se comienza generando una muestra inicial desde y luego se utiliza esta muestra para generar desde usando la red neuronal entrenada (llamada generador en el caso de la GAN y decoder en el caso del VAE). En modelos secuenciales como los ARMs o los DMs, se comienza con una muestra inicial desde el nodo raíz (token inicial en ARMs y ruido inicial en DMs) y luego se decodifica iterativamente de forma secuencial (de forma causal en los ARMs y de forma anticausal en los DMs). En los modelos basados en score y EBMs en general (que no son redes bayesianas), dado que solo se suele conocer una cantidad proporcional a , la generación no es realizada con ancestral sampling, si no que se usan técnicas de Markov chain Monte Carlo (MCMC) ya que este tipo de algoritmos no necesita conocer la constante de normalización.
Algunas redes bayesianas usuales
La generalidad de las redes bayesianas permite ver varios modelos clásicos de machine learning, que usualmente se enseñan de manera independiente, como casos particulares de redes bayesianas.
Mixturas
Un modelo de mezclas (mixtura) consiste en combinar distribuciones independientes, , usando una variable latente que elige al azar una de las distribuciones para generar la muestra observable . Más precisamente, la distribución marginal asociada a la variable observable , es una combinación convexa de las distribuciones que se buscan mezclar:
Notar que esta distribución marginal se obtiene al marginalizar en el modelo de variable latente estándar, , donde es una distribución categórica y . En consecuencia, el DAG asociado a una mixtura es el siguiente:

DAG asociado a una mixtura.
Las mixturas más usuales, llamadas mixturas gaussianas, son las que consideran . Por otro lado, es útil notar que los modelos de variable latente más generales, donde es una variable latente continua, pueden ser vistos como una mixtura infinita de distribuciones.
Naïve Bayes
Naïve Bayes es un clasificador clásico que, a diferencia de otros clasificadores que aprenden directamente una distribución (como la regresión logística o los clasificadores usuales basados en redes neuronales), utiliza un enfoque generativo (i.e., aprende una distribución conjunta en vez de una distribución discriminativa ). Este clasificador factoriza la distribución conjunta de una muestra y su respectiva clase, , como
Es decir, esta red bayesiana asume que : las características (coordenadas) de una muestra son condicionalmente independientes si es que se conoce la etiqueta de clase (de aquí viene la parte ingenua o naïve). El DAG asociado a esta red bayesiana es el siguiente:
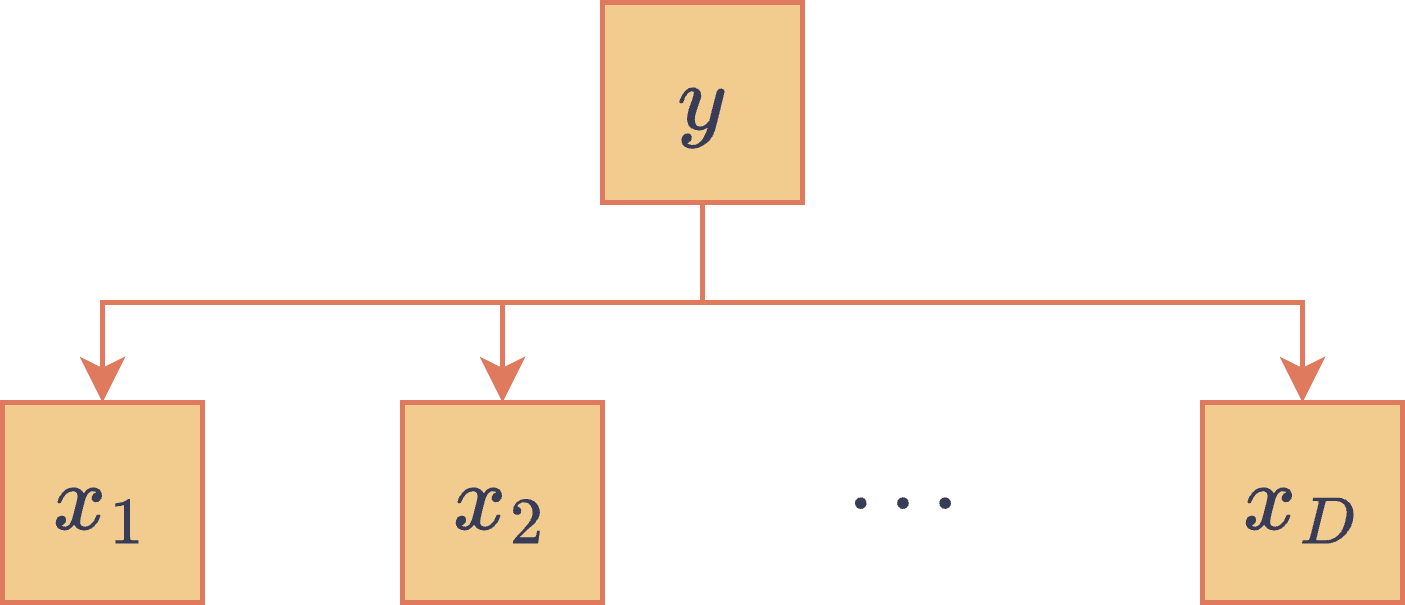
DAG asociado al clasificador Naïve Bayes.
Notar que en este DAG se separó la variable en sus componentes para poder separar las relaciones de independencia de cada coordenada. En otros grafos es usual agrupar todo el vector aleatorio en un mismo nodo cuando este puede ser visto como un mismo objeto en el sentido de las relaciones de dependencia e independencia.
En esta red bayesiana es una distribución categórica (ya que es una etiqueta de clase), mientras que cada distribución dependerá de la naturaleza de la variable aleatoria . Para realizar clasificación, este modelo calcula la posterior mediante la regla de Bayes y elige la clase más probable.
Cadenas de Markov
Cuando las variables del modelo, , tienen un comportamiento o interpretación secuencial, es usual considerar ciertas hipótesis de causalidad o independencia temporal. Una familia de modelos simples pero muy útiles en la práctica son las cadenas de Markov (de primer orden), las cuales asumen que el futuro es independiente del pasado si se conoce el presente, es decir: . En consecuencia, este tipo de modelos factoriza la distribución conjunta como
Dada la forma en la que se van generando las muestras según el algoritmo de ancestral sampling, a este tipo de modelos también se les dice autorregresivos de primer orden. Una elección usual, y que muchas veces es asumida sin siquiera mencionarlo, es considerar que la cadena de Markov es homogénea, es decir, es independiente de para todo (lo que puede verse como una forma de parameter tying). En este caso, si además cada variable es discreta, el kernel de transición puede ser guardado en una matriz estocástica, llamada matriz de transición: , para todo . El DAG asociado a una cadena de Markov es el siguiente:

DAG asociado a una cadena de Markov.
La condición de Markov se puede generalizar a un orden , donde cada variable depende de las variables anteriores, lo cual se representa con la hipótesis de independencia . En particular, si se están modelando secuencias de texto, cuando al modelo se le suele llamar bigrama y para se le llama trigrama. En general, se les llama -grama a los modelos de Markov de orden que modelan secuencias de texto utilizando gramas (unidad básica de texto, como una letra o una palabra). En el caso extremo , donde todos los tokens son independientes (pensar, por ahora, un token como una palabra dentro de un texto), el modelo se llama unigrama o bag-of-words (BoW). El otro caso extremo, , corresponde a no realizar ninguna hipótesis de independencia, recuperando la regla de la cadena.
Por otro lado, los procesos forward y backward asociados a los modelos de difusión son cadenas de Markov, al igual que los flujos normalizantes. En general, la forma relativamente simple que tienen las cadenas de Markov para modelar procesos secuenciales permite poder usarlas en una amplia cantidad de casos, por lo que este tipo de procesos suelen ser estudiados de forma especializada.
Modelos de Markov ocultos
Los modelos de Markov ocultos (HMM) son, al igual que las cadenas de Markov, redes bayesianas útiles para modelar secuencias de variables . La principal diferencia es que los HMM asumen la existencia de una cadena de Markov latente, , la cual va generando las observaciones visibles , donde cada elemento generado depende únicamente de la variable latente . Es decir:
En esta factorización, es la distribución inicial sobre los estados latentes, es el kernel de transición entre los estados latentes y es la distribución de emisión, la cual modela cómo cada estado latente genera su respectiva observación. El DAG asociado a un HMM es el siguiente:
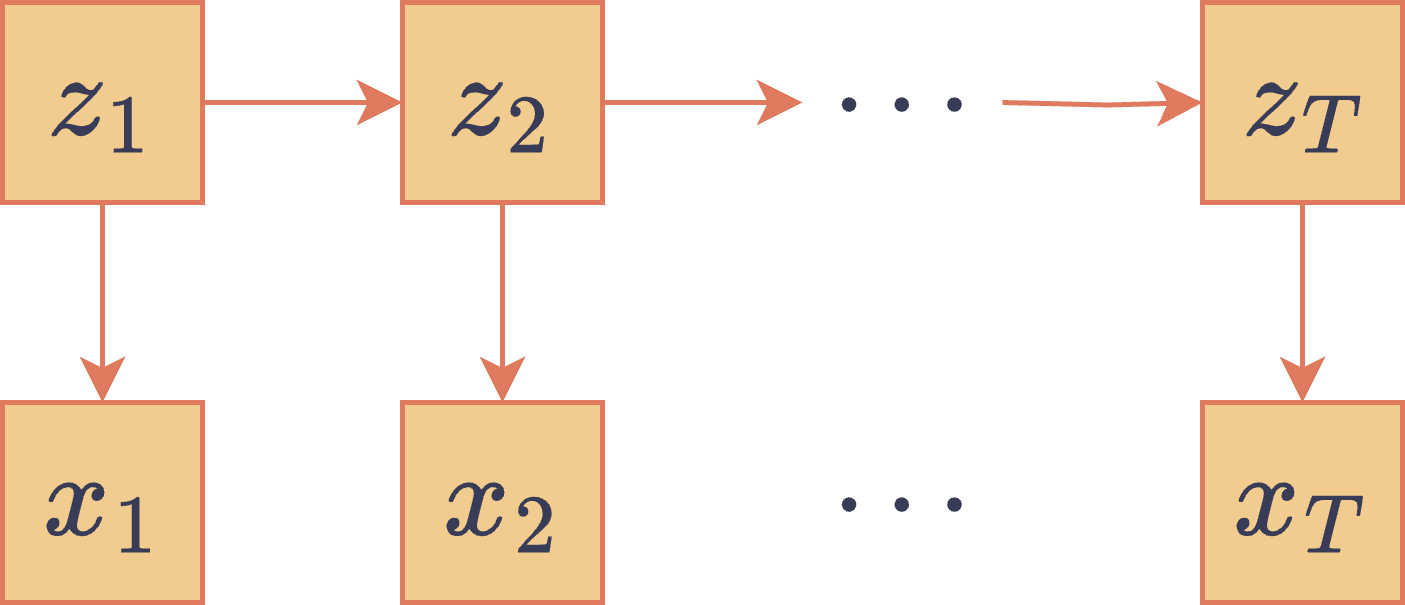
DAG asociado a un modelo de Markov oculto.
Si bien los HMMs se pueden usar en diversos campos, en NLP es usual ver este tipo de modelos en tareas de etiquetado de secuencias de texto como POS tagging (busca etiquetar cada palabra con su categoría gramatical como sustantivo o verbo) y NER (busca identificar palabras que son entidades como personas o lugares), donde es necesario asignarle una clase a cada uno de los tokens del texto a analizar. Por otro lado, si bien este tipo de modelos podría usarse para generación de texto, la independencia condicional entre los tokens no permitiría generar frases con mucho sentido.
Modelos generativos modernos
Formulación naïve
Muchos de los modelos generativos actuales están basados en redes neuronales entrenadas para aprender a aproximar una distribución desconocida utilizando únicamente un conjunto de entrenamiento, , donde (se asume que) cada muestra fue generada de manera independiente a partir de . Una forma directa de hacer esto es considerar la distribución empírica, la cual le asigna una masa uniforme únicamente a las muestras observadas en el entrenamiento. Es decir, la función de masa de la distribución empírica es
donde es la medida de Dirac centrada en la muestra .
Sin embargo, esta distribución es poco útil para ser usada en un proceso generativo ya que solo asigna masa a las muestras observadas en el conjunto de entrenamiento , lo que no permite variabilidad en la generación más allá de este conjunto. Una posible regularización a este enfoque consiste en utilizar kernel density estimation (KDE), lo cual puede verse como una versión suavizada de la distribución empírica. Si es un kernel de densidad (i.e., una función de densidad con ), entonces la distribución que entrega KDE es un promedio de estos kernels centrados en cada una de las muestras en :
La función suele interpretarse como una versión suave de la medida de Dirac, , debido a que suele entregar masa a los vecinos de (generalmente decayendo a medida que se alejan de ), mientras que concentra toda su masa en .
En las siguientes figuras se pueden ver ejemplos de KDE para (izquierda) y (derecha). En ambos casos, está formado por 5 puntos generados al azar sobre el intervalo (izquierda) y sobre el cuadrado (derecha). El kernel usado en ambos casos es un kernel gaussiano, (con un hiperparámetro), el cual permite colocar una campana gaussiana en cada uno de los puntos de , de forma similar a como ocurre en una mixtura gaussiana con prior uniforme. Dado que el kernel depende únicamente de la cantidad , este kernel también se suele llamar kernel de base radial (RBF kernel) ya que, como se observa en el mapa de calor, genera curvas de nivel circulares.
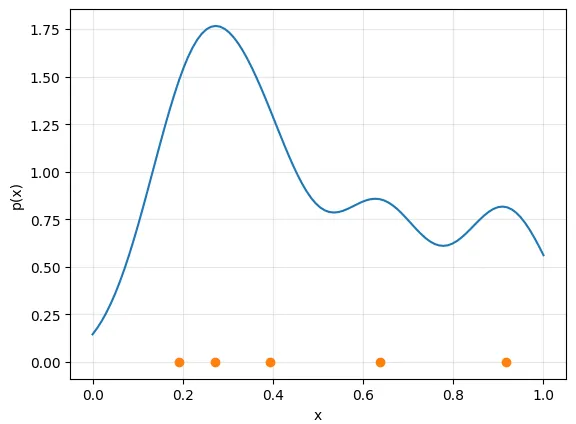
KDE en .
Código para generar la figura.
import numpy as np import matplotlib.pyplot as plt def gaussian_kernel(x, xi, bandwidth): return np.exp(-0.5 * ((x - xi) / bandwidth) ** 2) / (np.sqrt(2 * np.pi) * bandwidth) def kde(data, x_grid, bandwidth=0.1): return np.mean([gaussian_kernel(x_grid, xi, bandwidth) for xi in data], axis=0) data = np.random.rand(5) x = np.linspace(0, 1, 100) density = kde(data, x) plt.plot(x, density) plt.plot(data, np.zeros_like(data), 'o') plt.xlabel('x') plt.ylabel('p(x)') plt.show()
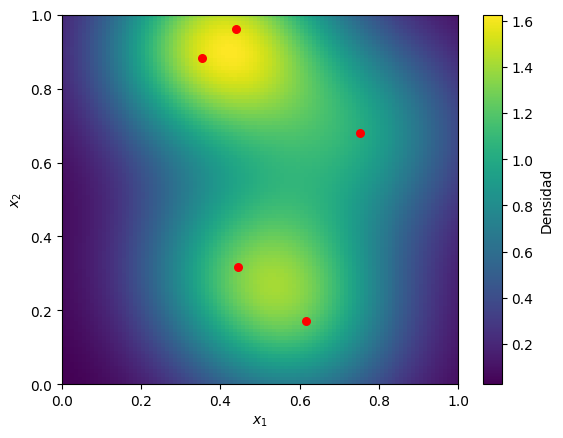
KDE en .
Código para generar la figura.
import numpy as np import matplotlib.pyplot as plt def gaussian_kernel(x, y, xi, yi, bandwidth): return np.exp(-0.5 * (((x - xi) ** 2 + (y - yi) ** 2) / bandwidth ** 2)) / (2 * np.pi * bandwidth ** 2) def kde(data, x_grid, y_grid, bandwidth=0.2): density = np.zeros_like(x_grid, dtype=float) for xi, yi in zip(data[0], data[1]): density += gaussian_kernel(x_grid, y_grid, xi, yi, bandwidth) return density / len(data[0]) data = np.random.rand(2, 5) x_grid, y_grid = np.meshgrid(np.linspace(0, 1, 100), np.linspace(0, 1, 100)) density = kde(data, x_grid, y_grid) plt.imshow(density, origin='lower', extent=[0, 1, 0, 1], cmap='viridis', aspect='auto') plt.colorbar(label='Densidad') plt.scatter(data[0], data[1], c='red', s=30) plt.xlabel(r'$x_1$') plt.ylabel(r'$x_2$') plt.show()
En ambos casos, el hiperparámetro (asociado a la desviación estándar en una distribución gaussiana) determina a qué velocidad decae la densidad en a medida que las posibles muestras se alejan de las muestras observadas en : un valor pequeño puede capturar con precisión variaciones locales, pero puede producir overfitting al poder capturar también el ruido en las muestras, mientras que un más grande, si bien genera una densidad más suave, pero puede producir underfitting al limitarse a distribuciones de baja frecuencia.
Paradigmas generativos actuales
Si bien KDE puede funcionar bien en baja dimensión, sufre de la maldición de la dimensionalidad, por lo que no se puede utilizar en contextos como generación de texto o imágenes. Más aún, no es claro cómo utilizar este enfoque para tareas más complejas como edición de imágenes o chatbots. En consecuencia, hay que buscar enfoques más robustos, como aquellos basados en verosimilitud o que se haya probado que, al menos en la práctica, funcionan bien. Dentro de esta familia de modelos, se encuentran los 6 paradigmas mencionados en la introducción. A excepción de los modelos basados en energía, todos estos paradigmas pueden verse como un tipo específico de red bayesiana:
Modelos autorregresivos (ARMs)
Este tipo de modelos se suele utilizar para modelar la generación de secuencias temporales. Si es una secuencia de variables (se asumirá fijo por simplicidad, pensado como un largo de secuencia máximo), la red bayesiana asociada a un ARM corresponde a factorizar la distribución conjunta siguiendo la regla de la cadena y no asumir, en principio, ninguna independencia (aunque impone como orden topológico del grafo al orden temporal de las variables):
El DAG que representa esta red bayesiana es el siguiente:
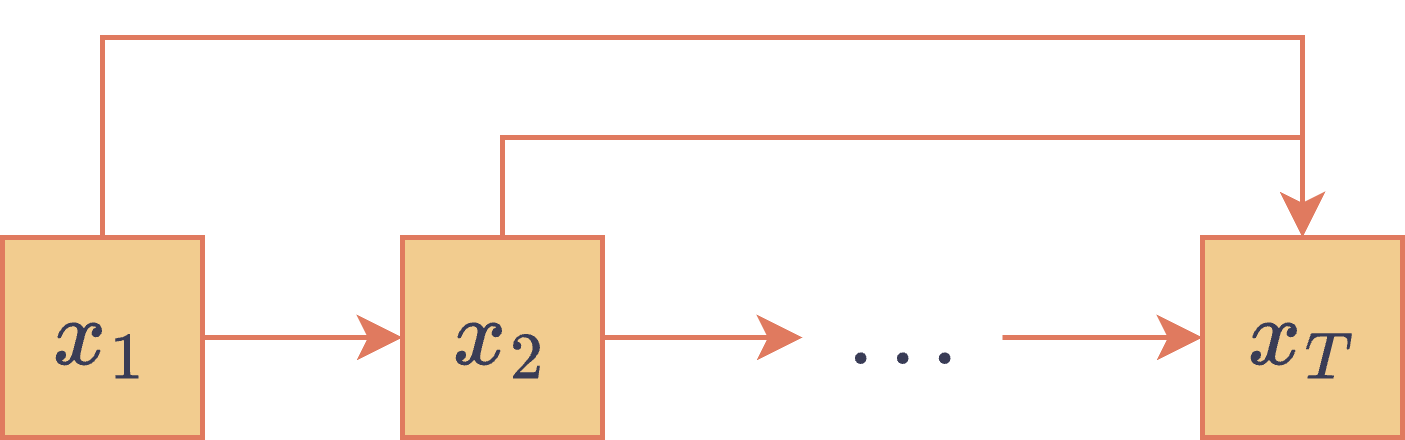
DAG asociado a un modelo autorregresivo.
Hasta hace no mucho tiempo, las distribuciones condicionales solían ser aprendidas usando redes neuronales recurrentes como la LSTM o la GRU. Sin embargo, hoy en día es más usual el uso de arquitecturas tipo Transformer debido a sus ventajas de paralelización y memoria temporal. Por otro lado, el hecho de no tener variables ocultas permite entrenar estos modelos usando el criterio de máxima verosimilitud, lo cual deja de ser posible en los siguientes paradigmas (al menos de forma exacta).
Autoencoders variacionales (VAEs)
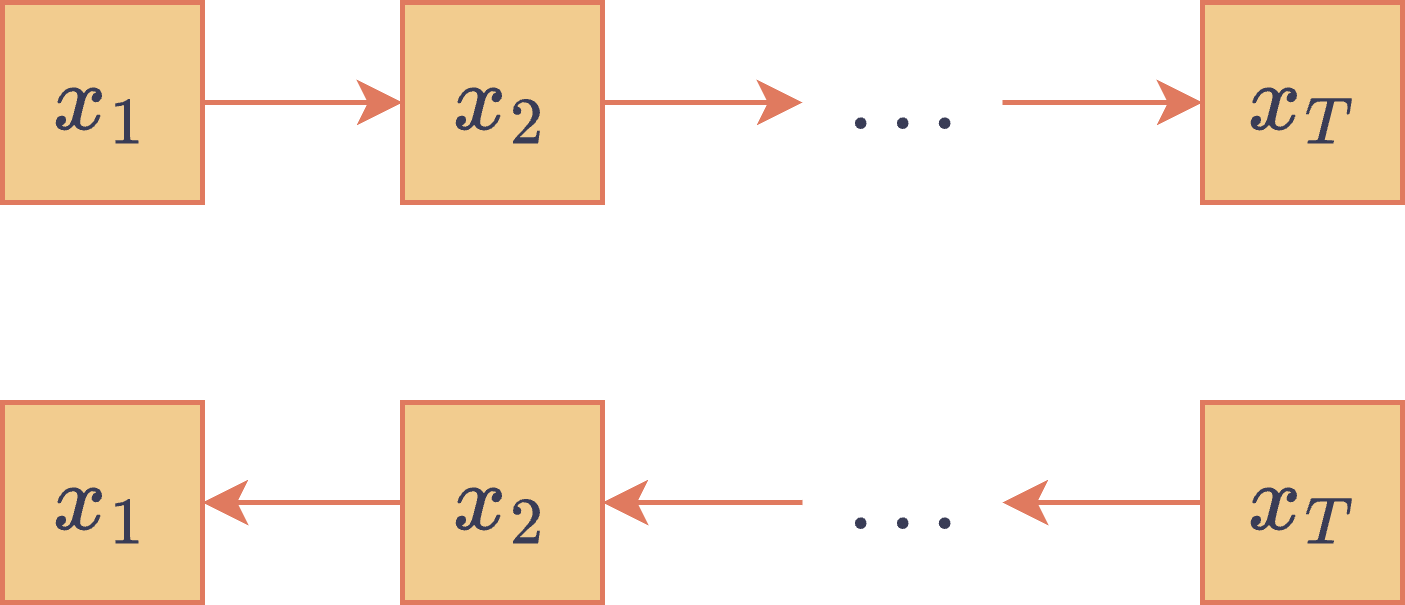
Esta familia de modelos formula el proceso generativo como un modelo de variable latente, , con la particularidad de que al mismo tiempo también aprenden otro modelo que es entrenado para estimar la distribución posterior . Si bien estos modelos no pueden ser optimizados usando el criterio de máxima verosimilitud (debido a que se vuelve intratable en modelos complejos), el uso de estos dos modelos permite encontrar una función de costo robusta, llamada ELBO, la cual sí se puede calcular de manera eficiente para el entrenamiento. Los DAGs de un VAE son los siguientes:

DAGs asociados a un VAE.
Los parámetros de la distribución condicional (que genera una muestra a partir de un valor de la variable latente ) suelen ser aprendidos por una red neuronal, llamada decoder, la cual recibe como entrada el valor de la variable latente . Por otro lado, los parámetros de la distribución condicional (que recupera la variable latente a partir de una muestra observada ) suelen ser aprendidos por otra red neuronal diferente, llamada encoder, la cual recibe como entrada una muestra . Considerando que usualmente se utiliza , este tipo de modelos tiene forma de autoencoder, de donde viene su nombre. La parte variacional tiene que ver con su función de costo, la cual resulta ser una cota inferior de la log-verosimilitud que se obtiene usando inferencia variacional.
Redes generativas adversarias (GANs)
Las GANs también son modelos de variable latente de la forma solo que, a diferencia de los VAEs que además incluyen un encoder, este tipo de modelos incluye un clasificador externo, , que es desechado después del entrenamiento. La idea principal de una GAN es que el clasificador aprenda a reconocer si una muestra dada, , es una muestra artificial () generada desde o si es una muestra real () generada desde la distribución desconocida . De este modo, mientras el clasificador es entrenado para esta tarea, el generador es entrenado para engañar al clasificador (i.e., busca que identifique las muestras generadas desde como reales), lo que genera como consecuencia que el generador aprenda a imitar muy bien las muestras que se generan desde . Los DAGs asociados a una GAN son muy similares a los de un VAE:

DAGs asociados a una GAN.
En este caso, al modelo se le llama generador (no se usa la interpretación encoder-decoder), mientras que al clasificador se le suele llamar discriminador.
Modelos de difusión (DMs)
Este tipo de modelos está compuesto por dos distribuciones distintas. Una primera distribución (fija) inyecta ruido de manera progresiva a muestras de hasta llegar a una imagen de puro ruido. Dado que el ruido se va inyectando directamente sobre la imagen ruidosa anterior, este proceso de destrucción de información puede ser expresado como una cadena de Markov:
donde (con ) son transiciones ruidosas tales que . Al mismo tiempo, otra red bayesiana es entrenada para aprender a deshacer el proceso de inyección de ruido. Esta red bayesiana, cuyos parámetros son aprendidos por una red neuronal, también es una cadena de Markov pero hacia atrás en el tiempo (ya que busca revertir la cadena de Markov que inyecta el ruido):
donde es el nodo raíz de esta red bayesiana. Los DAGs asociados a ambos modelos gráficos son los siguientes:
DAGs asociados a un modelo de difusión.
Una vez se tiene entrenada la red neuronal para , se puede generar una nueva muestra comenzando con una muestra generada desde y aplicando el proceso de denoising aprendido para llegar a una muestra , la cual debería parecerse a una muestra de si el modelo de difusión fue bien entrenado.
Flujos normalizantes (NFs)
El paradigma de los flujos normalizantes modela una distribución de probabilidad mediante la transformación de una variable aleatoria simple y bien conocida a través de una serie de funciones invertibles y diferenciables. La red bayesiana asociada a estos modelos puede verse, al igual que los modelos anteriores, como un modelo de variable latente , donde la distribución es determinista, es decir, , cuando se conoce el valor de . Dado que la transformación se considera invertible y de inversa diferenciable (i.e., es un difeomorfismo), el teorema de cambio de variable permite obtener la densidad a partir de la densidad :
Por lo general, la transformación se construye componiendo varias transformaciones más simples, , por lo que el jacobiano se puede descomponer, de acuerdo a la regla de la cadena (para derivadas), como el producto de varios jacobianos individuales.
El DAG asociado a un modelo basado en flujos normalizantes se puede ver, dependiendo de la dirección temporal que se elija, de dos formas distintas:
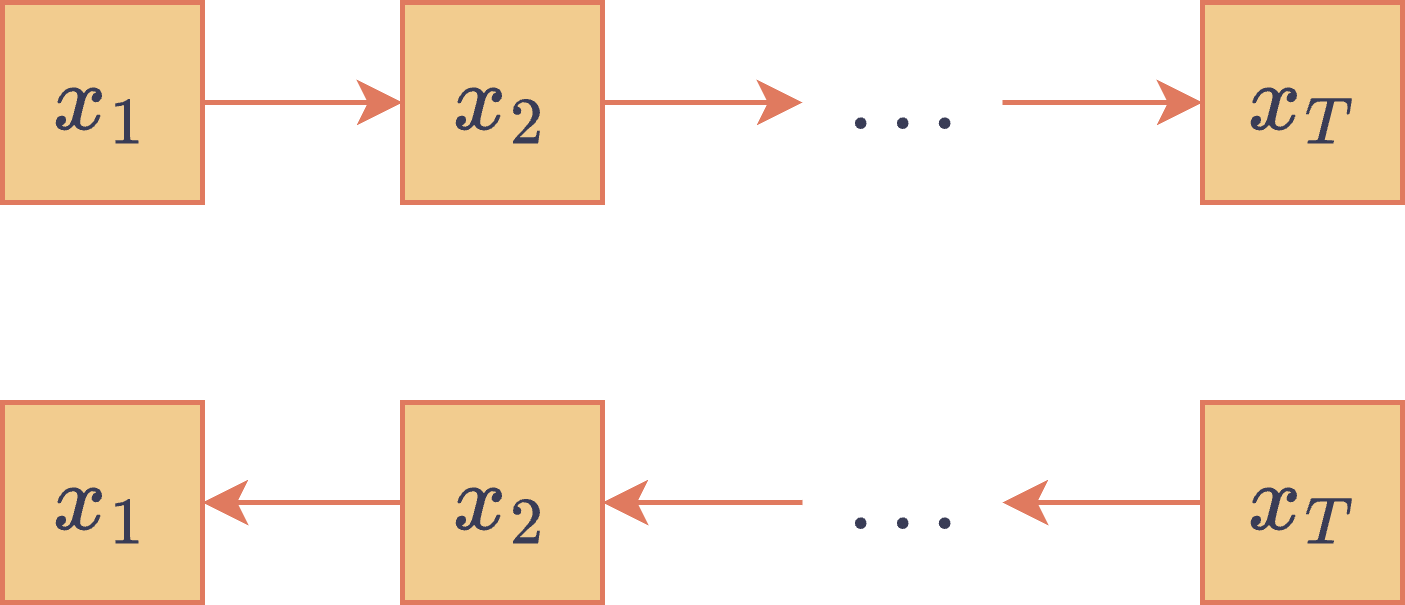
DAGs asociados a un modelo de flujos normalizantes.
Por último, es importante notar que cada paradigma utiliza un enfoque distinto para resolver el problema de aprender una distribución desconocida, cada uno aprovechando suposiciones e hipótesis de independencia distintas, lo cual le otorga a cada enfoque propiedades únicas, tanto en su forma de entrenar, como en el tipo de generación que realiza. Por otro lado, es interesante mencionar que todos los modelos tienen, de un modo u otro, alguna conexión con la física termodinámica: los ARMs usan la idea de temperatura para controlar la diversidad en la generación; los VAEs y los DMs entrenan una cantidad llamada ELBO, la cual puede relacionarse con la energía libre de Helmholtz; y los EBMs se basan en escribir la función de densidad como una distribución de Boltzmann y modelan directamente una función de energía.
Modelos generativos condicionales
Hasta el momento, todos los modelos generativos han sido formulados para aprender una distribución que aproxime bien a otra distribución desconocida, . Sin embargo, en muchos casos prácticos se dispone de información adicional que se quiere que influya en la generación de los datos. Esto da lugar a los modelos generativos condicionales, donde en lugar de modelar una distribución incondicional , se modela una distribución condicional , con representando una variable observada que actúa como entrada adicional al modelo y que busca modificar el comportamiento de la distribución. Este tipo de condicionamiento es el que permite generar imágenes dada una descripción o conversar con un chatbot (en vez de generar texto libre). En estos casos, a la condición se le suele llamar prompt.
Los modelos condicionales, junto a la capacidad de multimodalidad (esto es, procesar varias modalidades: texto, imágenes, sonido, videos, etc.), permiten resolver algunas tareas que parecen difíciles (o hasta imposibles) de resolver con otros enfoques más clásicos, por ejemplo:
Traducción de texto: la arquitectura Transformer [1] (y otras arquitecturas seq2seq [2]) son diseñadas para aprender un modelo condicional que es capaz de traducir un texto de entrada a otro idioma (texto de salida ). En la arquitectura Transformer el texto es codificado mediante un mecanismo de auto-atención, mientras que la información condicional es inyectada al modelo mediante un mecanismo de atención cruzada.
Generación de imágenes a partir de texto: modelos como DALL-E [3] y Stable Diffusion [4] permiten generar imágenes a partir de descripciones textuales. En este caso, los modelos aprenden una distribución condicional donde es la imagen generada e es el texto dado como entrada (prompt). En el caso de DALL-E, es modelado por un modelo autorregresivo, mientras que en Stable Diffusion, es modelado por un modelo de difusión. El éxito de los modelos de difusión llevó a OpenAI a cambiar a este paradigma para diseñar DALL-E 2 [5] y DALL-E 3 [6].
Traducción y modificación de imágenes: modelos como pix2pix [7] y CycleGAN [8] (ambos modelos tipo GAN) o FLUX.1 Kontext [9] (modelo de flow matching) permiten realizar tareas sobre imágenes como colorización de imágenes en escala de grises e inpainting (imputación de píxeles, por ejemplo, para corregir detalles estéticos). En todos estos casos, es la imagen generada e es la imagen de entrada. De forma similar se pueden modelar otras tareas como super-resolución.
Automatic speech recognition (ASR): modelos como Whisper [10] (modelo tipo Transformer que procesa secuencias de audio en vez de secuencias de texto) permiten transcribir grabaciones de voz modelando una distribución condicional , donde es una pista de audio y es una secuencia de texto. La tarea inversa, la cual consiste en modelar , permitiría resolver la tarea de generar un audio de voz a partir del texto que se debe hablar en el audio.
En este tipo de modelos, la generación de nuevas muestras depende explícitamente del valor del factor condicionante , el cual es necesario para controlar y dirigir el proceso de generación dependiendo de qué valor se entregue como entrada adicional al modelo. Por otro lado, es importante notar que cualquier red bayesiana incondicional, , puede ser transformada en una red bayesiana condicional, agregando a cada uno de los factores:
Más aún, dado que cada factor suele ser aprendido por una red neuronal (cuya entrada son los valores de las variables aleatorias ), la misma arquitectura neuronal usada para aprender (los parámetros de) suele ser adaptada para aprender (los parámetros de) la distribución condicional . Para esto, basta modificar la red neuronal para poder inyectar, de algún modo, el valor de en el input. Una forma fácil y que muchas veces funciona es concatenar el valor de al resto de entradas de la red neuronal, aunque también es posible utilizar mecanismos más complejos. Por ejemplo, Stable Diffusion inyecta el prompt al proceso de generación utilizando un mecanismo de atención cruzada, mientras que la arquitectura DiT [11] (Diffusion Transformer) inyecta la condición mediante moduladores tipo FiLM [12].
Esta facilidad para transformar una arquitectura incondicional en una arquitectura condicional ha permitido un rápido desarrollo de los modelos generativos multimodales (MLLMs). Encontrando formas eficientes de representar imágenes como vectores (o tensores de algún rango mayor), un modelo de lenguaje como GPT 4 puede ser transformado a un modelo que permita recibir adicionalmente imágenes como entrada, al igual que, por ejemplo, el modelo GPT 4o. De forma análoga se puede condicionar cualquier modelo generativo basado en redes neuronales con respecto a otras modalidades como video, temperatura, movimiento, etc., siempre y cuando se conozca una forma eficiente de inyectar la información condicional en la red neuronal. A la representación vectorial de una entrada en alguna modalidad específica se le suele llamar vector de embedding, mientras que al modelo que transforma dicha modalidad en una representación vectorial se le suele llamar modelo de embedding o capa de embedding en el caso de estar dentro de un modelo más grande.
Para mayor simplicidad, por lo general se considerarán modelos generativos incondicionales al momento de formular los distintos paradigmas, pero siempre hay que tener en cuenta que el enfoque utilizado actualmente (basado en redes neuronales) permite añadir condiciones adicionales al modelo gráfico como entradas adicionales a las redes neuronales sin mayor complejidad. Más aún, por lo general uno siempre desea tener un modelo generativo condicional ya que no suele ser suficiente tener un modelo que genere objetos (e.g., imágenes o texto) de forma libre, sino que se busca poder guiar el proceso de generación (e.g., mediante un prompt) para obtener resultados útiles para el usuario final.
Por último, es importante notar que para construir un modelo generativo condicional es necesario aprender una distribución (que se puede considerar como el opuesto bayesiano de un clasificador), por lo que es necesario, al igual que en el caso supervisado, tener pares condición-muestra para el entrenamiento (aunque no siempre; algunos modelos condicionales siguen un enfoque autosupervisado). Sin embargo, la obtención de estos datos etiquetados muchas veces es más fácil que en un clasificador clásico. Por ejemplo, para obtener un dataset de imágenes con texto descriptivo, se pueden obtener los captions a partir del texto alternativo de imágenes sacadas de internet.
Relación con los modelos discriminativos
Por lo general, un curso clásico de machine learning o deep learning se enfoca principalmente en estudiar tópicos de aprendizaje supervisado donde, por ejemplo, una red neuronal aprende a discriminar a partir de múltiples ejemplos etiquetados. Es decir, el modelo aprende una distribución condicional que aprende a reconocer el grupo al que pertenece una muestra. Por esto, a este tipo de modelos se les llama modelos discriminativos.
Dado un modelo generativo , siempre es posible, al menos en teoría, obtener un modelo discriminativo considerando que . Sin embargo, si la tarea objetivo es de tipo discriminativa (e.g., un clasificador), por lo general se obtiene un mejor desempeño entrenando directamente un modelo en vez de adaptar un modelo generativo a su versión discriminativa. Esto es esperable ya que ambos enfoques siguen paradigmas de entrenamiento distintos, donde los modelos discriminativos son entrenados precisamente para rendir bien en la tarea de clasificación. Por otro lado, un modelo discriminativo solo se enfoca en aprender a clasificar objetos en categorías predefinidas, sin modelar la estructura subyacente de los datos mediante el aprendizaje de la distribución . En cambio, un modelo discriminativo obtenido a partir de un modelo generativo aprende ambas distribuciones al aprender la distribución conjunta . En consecuencia, los modelos generativos suelen tener un mejor entendimiento del mundo que los modelos discriminativos, ya que un modelo discriminativo no puede, por ejemplo, generar nuevas muestras a partir de una clase determinada. Además, los modelos discriminativos pueden ser vulnerables a ataques adversarios, donde se ha demostrado que pequeñas modificaciones en la entrada pueden cambiar totalmente la predicción. En cambio, un modelo discriminativo obtenido a partir de uno generativo podría ser más robusto a estas perturbaciones. Más aún, en problemas de aprendizaje semisupervisado, donde hay pocos ejemplos etiquetados y muchos sin etiquetar, los modelos generativos pueden ser útiles para mejorar el clasificador final.
Otra observación importante es que hasta hace no muchos años, los principales avances en deep learning (e.g., AlexNet, ResNet y EfficientNet) correspondían a modelos usados para aprendizaje supervisado, ya que se daba por hecho que las tareas generativas estaban limitadas solo a los humanos. Sin embargo, en los últimos diez años, el mayor progreso ha estado dominado por los modelos generativos, los cuales son, usualmente, de naturaleza no supervisada. Parte de este rápido desarrollo es gracias a las técnicas desarrolladas en modelos discriminativos, las cuales han sido adaptadas a modelos generativos. Dentro de estas técnicas se encuentran muchas de las mejoras en arquitecturas neuronales (e.g., ReLU, bloques residuales, dropout, BatchNorm), pero también se encuentran mejoras en los frameworks y en el hardware usado.
Modelos de variable latente
En el ejemplo inicial, todas las variables del modelo pueden ser observadas (es decir, además de conocer sus distribuciones, se puede conocer el valor que toman), por lo que se dice que el modelo es completamente observable. Sin embargo, en modelos probabilísticos más complejos, es común que algunas variables del sistema no sean directamente observables, sino que sean variables latentes (también llamadas variables ocultas), las cuales se suelen considerar como variables ficticias que influyen sobre las variables observadas, permitiendo, además, explicar la variabilidad de los datos observados. A modo de ejemplo, las imágenes del dataset CelebA [13] (dataset de imágenes de caras) se representan como vectores de dimensión . Sin embargo, uno puede hipotetizar que las imágenes fueron generadas transformando una variable aleatoria oculta (que vive en un espacio de dimensión ) al espacio ambiente . Este espacio latente podría ser un conjunto de variables más primitivas como el sexo de la persona en la fotografía, su color de pelo, el color de sus ojos, su color de piel, si usa lentes o no, si usa sombrero, etc., y las distintas imágenes que se puedan obtener una vez se definen estas variables latentes vienen dadas por la aleatoriedad del proceso de generación.
El uso de modelos de variables ocultas se suele justificar mediante la manifold hypothesis, la cual propone que los datos observados viven en un espacio ambiente de alta dimensión, , pero que realmente provienen de un espacio (más precisamente, una variedad diferenciable) de menor dimensión, . La hipótesis de la variedad es una hipótesis bastante aceptada (con evidencia empírica) y permite, entre otras cosas, explicar la aparente ausencia de la maldición de la dimensionalidad (a.k.a. efecto Hughes) al entrenar redes neuronales. Por otro lado, el uso de los modelos de variable latente permite construir formas ingeniosas de formular distintos enfoques generativos, los cuales muchas veces no tienen relación entre sí más que ser modelos de variable latente. Por ejemplo, las GANs y los VAEs son dos tipos de modelo generativo de variable latente que funcionan de manera muy diferente. Cada uno de estos paradigmas, al ser entrenados bajo criterios distintos, pueden aprender comportamientos y patrones distintos, incluso si son entrenados sobre un mismo conjunto de datos. Por ejemplo, en el caso de las GANs y los VAEs, se observa que las GANs son buenas generando de forma clara los bordes de los objetos, mientras que los VAEs generan bordes más borrosos. Sin embargo, las GANs tienen dificultades para aprender muestras con mayor variabilidad, mientras que los VAEs son capaces de capturar mejor el soporte de la distribución desconocida que se busca aproximar.
En la siguiente figura se ve el dataset swiss roll [14], el cual será usado en todas las implementaciones iniciales (excepto en los ARMs) para introducir cada uno de los paradigmas generativos. En línea con la hipótesis de la variedad, se observa que, si bien las muestras viven en el espacio ambiente , estas siguen una estructura que pareciera poder explicarse, al menos de forma aproximada, con solo dos grados de libertad.
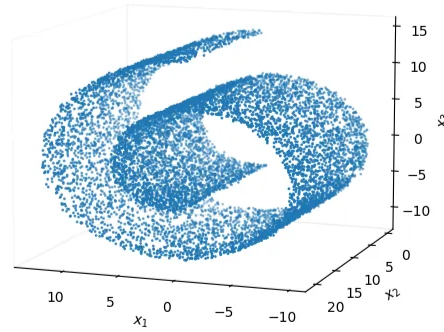
Swiss roll [14].
Código para la figura.
import matplotlib.pyplot as plt from sklearn.datasets import make_swiss_roll x, _ = make_swiss_roll(10000, noise=0.1) fig = plt.figure(figsize=(8, 6)) ax = fig.add_subplot(111, projection='3d') ax.scatter(x[:, 0], x[:, 1], x[:, 2], s=1) ax.view_init(elev=10, azim=110) ax.xaxis.pane.fill = False ax.yaxis.pane.fill = False ax.zaxis.pane.fill = False ax.set_xlabel(r'$x_1$') ax.set_ylabel(r'$x_2$') ax.set_zlabel(r'$x_3$') ax.grid(False) plt.show()
Más en general, se han encontrado dimensiones intrínsecas para algunos datasets clásicos, lo que valida empíricamente la hipótesis de la manifold. Por ejemplo, para el dataset MNIST se ha probado experimentalmente que su dimensión intrínseca es cercana a 12, lo cual es considerablemente menor que la cantidad de pixeles de las imágenes de este dataset, donde . Por otro lado, en los casos donde la hipótesis de la variedad no se cumple (o donde no existe realmente una variable latente), el considerar un modelo de variable latente no perjudica la formulación ya que si el modelo real desconocido no fuese de variable latente, siempre se puede terminar aprendiendo que , es decir, .
Vista como una red bayesiana, la distribución conjunta de un modelo de variable latente se factoriza de forma causal como , donde es el prior (se llama así ya que no está condicionado a nada) sobre la variable latente y es la distribución condicional de los datos observados dado el valor de la variable latente (que no es lo mismo que la marginal ). En estos casos, el modelo se interpreta como un modelo generador, dada una semilla inicial , por lo que también se le conoce como decoder. Es importante notar que está representando todas las variables observables unidas en una única variable con el fin de simplificar la notación. Por ejemplo, para un modelo que modifica una imagen de acuerdo a una descripción, podría ser un vector formado por algún embedding de la imagen original y del texto con las instrucciones de edición. El mismo principio aplica para , por lo que a se le puede decir la variable latente o las variables latentes.
Por otra parte, a excepción de los modelos autorregresivos (usados en texto) y los modelos basados en energía (ya no tan usados en IA generativa, al menos en su versión original), todos los paradigmas generativos modernos son modelos de variable latente, por lo que es necesario hacer hipótesis sobre la distribución prior . Por lo general, es usual considerar ya que funciona bien al desarrollar la matemática de los distintos modelos y, además, es una distribución desde la que es fácil generar muestras. Esto último es una propiedad importante ya que prácticamente todos los modelos de variable latente (como las GANs, los VAEs o los modelos de difusión) funcionan generando una muestra latente inicial y luego generan una nueva muestra (e.g., una imagen) utilizando el valor de en la distribución . Además, al estar considerando una matriz de covarianzas diagonal en , se está imponiendo explícitamente que todas las coordenadas de la variable latente sean independientes entre sí, lo cual no es raro si se interpretan las variables latentes como el conjunto de características esenciales que poseerán las muestras que se generen desde .
Desde el punto de vista de la generación en modelos de variable latente, se observa que el algoritmo de ancestral sampling sí entrega muestras de la distribución marginal ya que
por lo que se puede ver el sampling como una aproximación de Monte Carlo (con una única muestra) de la esperanza .
A continuación se revisarán algunas de las ventajas que poseen los modelos generativos basados en variable latente.
Reducción de la dimensionalidad
Si bien el proceso generativo de un modelo de variable latente es de la forma , es posible considerar la dirección opuesta, , con el fin de recuperar la información primitiva que generó una muestra . Esta distribución posterior puede interpretarse como una representación (estocástica) más compacta de , la cual muchas veces es interpretable o útil. Por ejemplo, si es una distribución que genera imágenes aleatorias de círculos de color negro con una resolución de , el proceso de generación se podría reducir a una variable latente en que genera ternas con indicando el radio del círculo y las coordenadas de su centro. Con esto, la distribución generadora puede ser la función determinista que grafica el respectivo círculo y genera la imagen.
La tarea de aprender buenas representaciones latentes se denomina representation learning y puede ser vista como una forma robusta de hacer reducción de dimensionalidad. Por ejemplo, el modelo Stable Diffusion [4] de Stability AI entrena un modelo de variable latente (tipo VAE) para luego poder entrenar otro modelo generativo más potente (tipo difusión) en el espacio latente del modelo anterior. Esta técnica de aplicar un modelo generativo (e.g., difusión) en el espacio latente de otro modelo (e.g., un VAE) es usada prácticamente en todos los modelos generativos de variable latente que hay hoy en día ya que permite disminuir el costo y tiempo de entrenamiento considerablemente al poder trabajar con representaciones de menor dimensión.
Interpolación semántica en el espacio latente
La representación latente de una muestra , aparte de actuar como una representación más compacta de , suele ser semánticamente más rica que la representación original, en el sentido que es posible desplazarse en el espacio latente para cambiar algunas propiedades semánticas de la muestra, entregando una forma de interpolación semántica entre dos objetos.
Si son dos imágenes, una tarea natural es querer interpolar entre estas dos imágenes, realizando una transición suave de una imagen a otra. Un enfoque naïve es interpolar linealmente en el espacio de pixeles, donde se considera como imagen interpolada a , para . Esta interpolación consiste en ir desplazando cada pixel a lo largo de la recta que unen los pixeles homólogos en las imágenes y . Sin embargo, dado que los valores de los pixeles representan los colores de la imagen, esta interpolación es una interpolación lineal entre la intensidad de color de cada pixel individual, los cuales no contienen información semántica acerca de la imagen, por lo que la imagen interpolada, , suele ser una imagen sin mucho sentido.
Un enfoque que funciona mejor consiste en utilizar un modelo generativo de variable latente, . De este modo, si una función genera una muestra desde la distribución posterior (distribución obtenida, por ejemplo, usando la regla de Bayes), se pueden obtener representaciones latentes de y mediante y respectivamente. Con estas representaciones, se puede realizar una interpolación en el espacio latente del modelo generativo mediante . Luego, si genera una muestra desde la distribución , entonces es una imagen interpolada pero en el espacio latente de las imágenes y . Dado que el espacio latente suele estar asociado a atributos específicos de las muestras que se generarán, la interpolación en el espacio latente suele ser mucho más natural que la interpolación obtenida en el espacio de pixeles debido a que resulta ser una interpolación de propiedades esenciales de las muestras a generar y no solo una interpolación pixel a pixel. Por otro lado, si bien se podrían realizar otro tipo de interpolaciones en el espacio latente (e.g., slerp), la interpolación lineal suele ser suficiente. De hecho, algunos estudios han probado empíricamente que la variedad latente aprendida por los modelos de variable latente a menudo tiene una curvatura cercana a cero, por lo que se asemeja a un espacio euclidiano, donde la interpolación lineal es el método de interpolación natural.
En la siguiente imagen se observan interpolaciones semánticas en el espacio latente de una GAN, donde cada fila realiza la interpolación entre las imágenes de la primera y última columna:

Interpolación latente usando una DCGAN. Imagen obtenida desde [15].
Manipulación de atributos
Otra herramienta que entrega la continuidad del espacio latente es la posibilidad de modificar la intensidad de algún atributo de una muestra. Por ejemplo, en la siguiente imagen se modifica la intensidad del atributo sonrisa de la imagen que está en la primera columna:

Modificación de atributos usando un VAE. Imagen obtenida desde [16].
Para lograr esto, es necesario encontrar una dirección en el espacio latente que apunte hacia donde aumenta la intensidad del atributo que se quiere destacar en la variable observable. Luego, para una muestra , se puede desplazar su representación latente en esta dirección para aumentar (o disminuir) la intensidad del atributo en la muestra original.
Más precisamente, si es un conjunto de muestras que notoriamente poseen el atributo que se busca modificar (e.g., imágenes de personas sonriendo) y es un conjunto de muestras que notoriamente no poseen el atributo (e.g., imágenes de personas serias), entonces se pueden considerar los centroides latentes para ambos conjuntos:
De este modo, se puede considerar el vector director como la dirección latente asociada al atributo que se busca amplificar o aminorar. Luego, para y para una muestra generada desde , se puede considerar a como la muestra que aumentó () o disminuyó () la intensidad del atributo en la muestra . Este procedimiento permite trabajar con representaciones latentes interpretables, las cuales, además, permiten alterar propiedades de alto nivel mediante interpolación en el espacio latente. Sin embargo, hoy en día, la modificación de atributos suele realizarse mediante el uso de modelos condicionales que generan imágenes de acuerdo a una instrucción contenida en (prompt).
Por otro lado, es importante mencionar que por lo general no es posible encontrar una función para las GANs, por lo que este procedimiento solo se puede realizar cuando se conoce de antemano la variable latente que genera a la respectiva muestra . En cambio, los VAEs cuentan desde un comienzo con un modelo encoder, , por lo que sí es posible realizar este tipo de interpolaciones para muestras genéricas.
Estimación de parámetros
Dada una red bayesiana, para conocer la distribución conjunta es necesario y suficiente conocer cada uno de los factores que componen la factorización que asume la red bayesiana, . Si bien el desarrollo realizado hasta el momento permite considerar variables con valores desconocidos (variables latentes), siempre se ha asumido que todos los parámetros de las distribuciones son conocidos (e.g., si uno de los factores es una distribución gaussiana, se conocen los valores de su media y de su varianza para los distintos valores de las variables ). Sin embargo, en los modelos de IA generativa lo usual es no conocer dichos parámetros y solo contar con un conjunto de muestras (dataset de entrenamiento) generadas desde la distribución desconocida que se busca aprender. El proceso de estimar los valores de estos parámetros desconocidos (lo que usualmente se logra entrenando redes neuronales) se denomina inferencia, y la forma más usual de hacer inferencia (puntual) es siguiendo el criterio de máxima verosimilitud.
De manera general, inferir es la acción de obtener una conclusión lógica a partir de un conjunto de premisas que se asumen como ciertas. La inferencia estadística corresponde a realizar inferencia sobre una distribución a partir de un conjunto de muestras observadas, donde el objetivo más usual es inferir los parámetros de la distribución que (supuestamente) generó los datos. Dentro de la inferencia estadística se encuentra la inferencia bayesiana, donde se utiliza la regla de Bayes para hacer inferencia sobre variables desconocidas. De esta forma, la inferencia bayesiana evalúa la probabilidad de que una hipótesis sea cierta a partir de una creencia a priori sobre la hipótesis y de un conjunto de muestras observadas, las cuales actualizan la información asumida por el prior previo a la observación.
Sobre una red bayesiana, se pueden realizar 3 tipos de inferencia bayesiana: inferencia sobre variables no observadas (i.e., estimar el valor de variables desconocidas), inferencia sobre los parámetros de alguna de las distribuciones del grafo, e inferencia sobre el grafo mismo (i.e., aprender la estructura del grafo), aunque esta última tarea de inferencia no se trabajará. Para la tarea de inferencia sobre los valores de variables desconocidas, se puede considerar como ejemplo un modelo de variable latente , donde se asume que se conoce el valor de la variable observable pero no el valor de la variable latente . De este modo, se puede inferir la distribución posterior mediante la regla de Bayes:
Notar que la distribución marginal (o si es variable latente discreta) es costosa de obtener ya que requiere integrar (sumar en el caso discreto) sobre todos los posibles valores de la variable latente .
En las tareas de IA generativa, la red bayesiana de cada paradigma generativo suele ser conocida, por lo que no se debe hacer inferencia sobre el grafo. En cambio, el foco suele estar en hacer inferencia sobre los parámetros de las distribuciones del modelo gráfico, los cuales permitirán, posteriormente, generar nuevos datos utilizando las distribuciones aprendidas. Los modelos modernos consideran, por lo general, que cada uno de los factores sigue una distribución simple (e.g., una distribución gaussiana si es una variable continua o una distribución Bernoulli si es binario), lo que facilita el desarrollo de la matemática al construir las funciones de pérdida o demostrar propiedades necesarias para la formulación de los modelos. Dada la simpleza de las distribuciones comúnmente utilizadas, la complejidad de las distribuciones debe ser trasladada a los parámetros que las definen, lo cual se suele conseguir utilizando redes neuronales que estimen dichos parámetros. Por ejemplo, en el caso continuo donde se suele elegir , los parámetros y suelen ser las salidas de redes neuronales cuyas entradas son los valores de las variables en . Sin embargo, también es usual fijar algunos parámetros menos relevantes como las varianzas de las distribuciones gaussianas para poder disminuir la complejidad del modelo.
Si denota el vector de parámetros desconocidos de la distribución y (con ) denota el vector de todos los parámetros desconocidos de la red bayesiana, la forma usual de hacer inferencia sobre es considerar que estos parámetros también son variables del modelo cuyo valor no se conoce. De esta forma, se puede hacer inferencia sobre los parámetros haciendo inferencia sobre estas nuevas variables aleatorias. La distribución conjunta de este nuevo modelo extendido se factoriza como:
La distribución es un prior sobre los parámetros (recordar que se están tratando los parámetros como variables aleatorias), el cual se puede considerar uniforme () si no se quiere sesgar la estimación de los parámetros hacia ningún valor. La cantidad se llama verosimilitud (de los parámetros) e indica la probabilidad de generar la muestra observada cuando se considera el vector como los parámetros de la red bayesiana. De esta forma, se puede obtener la distribución posterior para los parámetros luego de conocer el valor de la variable conocida . Por regla de Bayes:
donde es la verosimilitud y la constante de normalización es una cantidad independiente de , la cual representa la probabilidad media de observar el valor conocido a lo largo de todos los posibles modelos (cada uno determinado por su respectivo valor de ).
De aquí en adelante se asumirá siempre que cada vector (parámetros de la distribución ) será estimado usando una red neuronal cuyas entradas serán los valores de las variables en y la salida será la estimación de la red neuronal para el vector de parámetros . Como es usual, si existe alguna restricción para , esta será impuesta en la última capa de la red neuronal. Por ejemplo, si debe ser un vector de probabilidad, es usual utilizar la función en la salida, mientras que si solo es un escalar que debe estar en el intervalo (e.g., para el parámetro de una distribución Bernoulli), es usual utilizar la función logística (llamada sigmoide en deep learning), . También es usual utilizar otras funciones de activación en la salida como por ejemplo , la cual restringe la salida al intervalo (notar que ), o , la cual filtra los valores negativos.
Máximo a posteriori
Cuando se realiza inferencia bayesiana sobre el vector de parámetros , la regla de Bayes entrega una distribución posterior , la cual corrige la distribución que asume el prior (recordar que ahora se está tratando a como variable aleatoria) teniendo en consideración el valor que tomó la variable . Sin embargo, muchas veces lo que realmente se busca es una estimación puntual de los parámetros y no una distribución completa (aunque esto último es más informativo que una estimación puntual). Más aún, la estimación usualmente no se realiza utilizando una única observación , sino que se utiliza un conjunto de observaciones, , las que se asumen como muestras provenientes desde . En consecuencia, la distribución posterior que se obtiene para los parámetros es , donde es la verosimilitud de una vez se conoce el conjunto de observaciones .
Un enfoque natural para elegir una estimación puntual de los parámetros a partir de la posterior es el de máximo a posteriori (MAP), el cual consiste en elegir a como el vector de parámetros más probable luego de conocer las observaciones en (i.e., como la moda de ):
Es importante notar que este enfoque entrega, por primera vez, una función objetivo con la cual se pueden entrenar las redes neuronales que estiman los parámetros de cada distribución de la red bayesiana.
Por otro lado, en vez de maximizar directamente la posterior , es más usual maximizar . Si bien ambos problemas son equivalentes (ya que el logaritmo es estrictamente creciente), en la siguiente sección se verá que el segundo problema es más estable numéricamente, lo cual es importante para un entrenamiento estable de las redes neuronales. De esta forma, el problema de optimización para el enfoque MAP es el siguiente:
Por simplicidad, de aquí en adelante se usará la notación estándar para indicar la distribución que sigue cuando se fijan los parámetros al valor . Del mismo modo, para cada factor de la red bayesiana, se escribirá . Además, si una distribución no lleva un símbolo de parámetro como subíndice, se asumirá que todos sus parámetros son conocidos (i.e., son distribuciones fijas). Esto último será usual al fijar, por ejemplo, distribuciones priors como una distribución estándar (e.g., en un modelo de variable latente).
Relación con weight decay
Reescribir la maximización de como la maximización de permite ver que algunas elecciones para el prior son equivalentes a aplicar técnicas de regularización clásicas durante la maximización de la verosimilitud. Por ejemplo, si se considera un prior gaussiano , con un hiperparámetro fijo, MAP resulta ser equivalente a maximizar la log-verosimilitud incluyendo regularización sobre los parámetros (llamado weight decay en PyTorch), lo cual es directo al ver que los problemas de optimización son equivalentes:
donde se usó que . Se observa que el parámetro de varianza inversa (precisión), , define la importancia que se le da al término regularizador, lo cual es esperable, ya que una varianza pequeña () concentra fuertemente su masa alrededor de la media de la distribución prior , mientras que una varianza alta () distribuye más uniformemente la masa sobre el soporte. De forma análoga, considerar un prior de Laplace equivale a utilizar LASSO (regularización ) sobre los parámetros. Notar que, en ambos casos, los priors están centrados alrededor del origen sesgando al modelo a usar parámetros pequeños, lo cual se espera que disminuya tanto la complejidad del modelo (para evitar overfitting) como su varianza (para un entrenamiento más estable).
También es posible hacer otras elecciones de priors convenientes para la optimización. Una alternativa usual en machine learning clásico es el uso de priors conjugados, donde se elige un prior con una forma específica tal que la posterior pertenezca a la misma familia, lo que resulta conveniente para el cálculo de productos que entrega la regla de Bayes. Sin embargo, si bien este enfoque suele entregar interpretabilidad al modelo, no se suele usar en modelos de IA generativa debido a que se prefiere elegir, implícitamente, un prior gaussiano al regularizar el entrenamiento usando weight decay.
Por último, es importante mencionar que algunas veces, sobre todo en la comunidad de machine learning, la expresión hacer inferencia se usa para referirse a la acción de realizar una predicción con un modelo ya entrenado y no a ajustar los parámetros de un modelo, a lo cual se le suele decir entrenar el modelo. Estos dos usos para el término inferencia no son contradictorios entre sí ya que realizar una predicción con un modelo puede verse como hacer inferencia sobre variables no conocidas. Sin embargo, es importante tener presente que, al menos desde una perspectiva bayesiana, entrenar un modelo también es una forma de realizar inferencia.
Criterio de máxima verosimilitud
Cuando se utiliza un prior uniforme sobre los parámetros, , el criterio de MAP se reduce al criterio de máxima verosimilitud, el cual es el enfoque estándar para la optimización de modelos probabilísticos en machine learning:
En IA generativa, todos los modelos que se estudiarán, a excepción de las GANs, se suelen entrenar siguiendo un enfoque relacionado, en algún sentido, con el enfoque de máxima verosimilitud.
Por otro lado, es usual asumir que todas las muestras en fueron generadas de forma independiente a partir de una distribución fija y desconocida, , por lo que se dice que las muestras en son independientes e idénticamente distribuidas (i.i.d.). Esta suposición motiva a considerar siempre una hipótesis de independencia condicional entre las muestras, , lo cual permite escribir . Más aún, esta independencia condicional permite descomponer la log-verosimilitud sobre todo el dataset de entrenamiento, , como una suma de log-verosimilitudes individuales:
Notar que esta separación en una suma es uno de los principales beneficios de optimizar la log-verosimilitud en vez de la verosimilitud directamente (donde quedaría un producto de verosimilitudes). Por otro lado, la mayoría de las distribuciones comúnmente usadas en machine learning (e.g., gaussiana o exponencial) son log-cóncavas (i.e., el logaritmo de su función de densidad es una función cóncava), por lo que para maximizar la log-verosimilitud basta derivar e igualar a cero (i.e., la condición de 1º orden necesaria para la optimalidad también es suficiente). Además, dado que las probabilidades están siempre en el intervalo , el producto de muchas probabilidades (e.g., en ) puede provocar problemas numéricos (y, por lo tanto, un entrenamiento inestable) al estar trabajando con números muy pequeños. Usando logaritmos, el producto se transforma en suma y el intervalo de probabilidades se estira a todo el semieje real .
Para fijar conceptos, dado un dataset , la función se denomina función de log-verosimilitud, y es una función de los parámetros y no de los datos observados (el conjunto de muestras se considera fijo, y cada conjunto define una función de log-verosimilitud distinta). Notar que la función de log-verosimilitud no es una (log-)distribución ya que, si bien es una distribución sobre , no lo es sobre debido a que . Por otro lado, el cálculo de la log-verosimilitud puede realizarse de forma secuencial (i.e., una muestra a la vez) o de forma paralela en batches, ya que la descomposición permite evaluar la log-verosimilitud de forma individual en cada muestra y luego sumar las salidas. Más aún, cuando el modelo no es de variable latente (i.e., todas las variables, a excepción de los parámetros, son observadas durante el entrenamiento), la optimización de los parámetros puede realizarse de forma independiente en cada nodo de la red bayesiana , lo que permite paralelizar el proceso de entrenamiento por nodos (e.g., se podría computar cada nodo en una GPU distinta si se están usando redes neuronales). En efecto, para una muestra de entrenamiento , su log-verosimilitud se descompone como:
por lo que, para obtener el estimador de máxima verosimilitud (MLE), se puede calcular individualmente el MLE para cada parámetro mediante ya que no influye en ningún otro sumando de la log-verosimilitud . Del mismo modo, si se realiza inferencia usando el conjunto de observaciones , el MLE para el parámetro se obtiene resolviendo el problema de optimización
La familia de modelos descrita anteriormente se denominan modelos totalmente observados ya que todas las variables del modelo, , son observadas en cada una de las muestras contenidas en el dataset de entrenamiento . Este tipo de modelos permite obtener la densidad de una muestra de forma exacta y tratable (solo se deben sumar términos). Más aún, el gradiente de la log-verosimilitud, , se puede obtener fácilmente mediante backpropagation, por lo que es fácil hacer inferencia sobre los parámetros de un modelo totalmente observado usando una red neuronal entrenada mediante el criterio de máxima verosimilitud. Más aún, si se trabaja con mini-batches de entrenamiento, , entonces la cantidad es un estimador insesgado de la verosimilitud media, , mientras que es un estimador insesgado del gradiente . Esta observación permite, por ejemplo, interpretar a como un gradiente estocástico que le entrega aleatoriedad al modelo (donde la aleatoriedad ocurre en la elección de las muestras que forman el batch ), lo cual muchas veces ayuda a evitar que el modelo se quede atrapado en un óptimo local de la función objetivo a optimizar. Por otro lado, el entrenamiento usando batches muchas veces es impuesto por restricciones de hardware, ya que para grandes modelos es usual no poder cargar todos los datos disponibles en la GPU para realizar el entrenamiento.
En conclusión, el criterio de máxima verosimilitud, , es el enfoque más común en modelos totalmente observados como los modelos autorregresivos (usados para generar texto) o los modelos basados en flujos (usados para generar imágenes). Esta función de pérdida permite optimizar los modelos de manera estable (dentro de lo posible; los Transformers a gran escala muchas veces presentan inestabilidades durante el entrenamiento aunque se entrenen usando verosimilitud), lo cual no siempre es así. Por ejemplo, las GANs, que entrenan un objetivo que no está basado en verosimilitud, sufren de muchas inestabilidades durante su entrenamiento, principalmente por la naturaleza adversativa de su entrenamiento.
Ejemplos
En algunos casos simples es posible encontrar el estimador de máxima verosimilitud de forma cerrada, el cual, aparte de ser único, también suele ser interpretable y natural. En esta subsección se revisarán algunos de estos casos.
MLE para la distribución gaussiana
Si es un dataset de muestras independientes, se puede considerar el modelo , donde es su media (desconocida) y es su varianza, la cual, por simplicidad, se asumirá conocida. Para buscar el estimador de máxima verosimilitud para el parámetro notar que
Para obtener se puede derivar la log-verosimilitud anterior e igualarla a 0 (condición de 1º orden):
Por lo que basta despejar para obtener el estimador de máxima verosimilitud:
Es decir, el MLE para la media de un modelo gaussiano es simplemente la media empírica de las muestras. Si bien se podría verificar que esta cantidad es un máximo mirando la segunda derivada (o el Hessiano en más dimensiones), aquí no es necesario porque la función a maximizar es cóncava (ya que la suma de funciones cóncavas es cóncava). Por otro lado, si también se quisiera estimar el parámetro , se puede realizar el mismo procedimiento para llegar a que el MLE de la varianza es simplemente la varianza empírica de las muestras en .
MLE para la distribución de Bernoulli
Si es un dataset de muestras binarias independientes, se puede considerar el modelo , donde es el parámetro (desconocido) de la distribución. Al igual que antes, este parámetro puede ser estimado usando el criterio de máxima verosimilitud. Para esto, notar que:
Al igual que antes, para obtener se derivará la log-verosimilitud anterior y se igualará a cero:
Por lo que basta despejar para obtener el estimador de máxima verosimilitud del parámetro desconocido:
Es decir, el MLE para una distribución de Bernoulli corresponde a la fracción de muestras con valor con respecto al total de muestras en , lo cual tiene sentido, por ejemplo, al interpretar el experimento como lanzamiento de monedas, donde la probabilidad de obtener cara, , es (cuando ) la cantidad de caras que se obtuvieron sobre el total de lanzamientos.
Por otro lado, al igual que en el caso gaussiano, este MLE para se puede ver como la media empírica de , la cual, a su vez, puede interpretarse como un estimador de la media real (asumiendo que , con desconocido).
MLE para la regresión lineal
Para un dataset supervisado (donde se asume que para una entrada dada), se puede considerar el modelo gaussiano lineal, (i.e., , con un error gaussiano aditivo), donde es el parámetro desconocido a estimar y es un hiperparámetro fijo (aunque también podría ser estimado por máxima verosimilitud). Al igual que antes, se puede obtener el estimador de máxima verosimilitud para , el cual coincide con el regresor lineal óptimo para mínimos cuadrados, , donde es la matriz cuya -ésima fila corresponde a la muestra , mientras que es el vector cuya -ésima coordenada es . Notar que, al igual que antes, este estimador de máxima verosimilitud también es natural ya que la matriz corresponde a la pseudoinversa de Moore-Penrose de la matriz , por lo que puede verse como un intento de despejar en un sistema lineal sobredeterminado, . Más aún, en línea con lo revisado en la sección anterior, si se agrega un prior gaussiano al parámetro desconocido , el estimador MAP coincide con el regresor lineal de mínimos cuadrados con regularización cuadrática (i.e., ridge regression).
Verosimilitud en modelos de variable latente
La principal dificultad de entrenar un modelo de variable latente por máxima verosimilitud es que la cantidad es costosa de computar. En efecto, para una red bayesiana de variable latente, , el cálculo de la log-verosimilitud requiere marginalizar sobre la variable latente :
Esta integral (o suma si es una variable latente discreta) es muy costosa de calcular, incluso aproximándola numéricamente (hay varias formas de hacerlo; una usual es escribir la igualdad anterior como , lo que permite usar una aproximación de Monte Carlo usando muestras desde ), por lo que la verosimilitud para este tipo de modelos se considera intratable en la práctica. Esta dificultad aumenta aún más si se considera que, por lo general, la verosimilitud se debe calcular para un dataset de muestras, , y en cada iteración del algoritmo de gradiente (asumiendo que los parámetros están siendo aprendidos por redes neuronales).
Por otro lado, la dificultad de calcular se hereda al querer calcular el gradiente (necesario para el entrenamiento de las redes neuronales) y al querer hacer inferencia sobre mediante . Además, la marginalización necesaria para calcular elimina la posibilidad de optimizar cada nodo del DAG de forma individual como sí ocurre en los modelos completamente observables. En efecto:
Dado que el logaritmo no distribuye sobre la integral, la log-verosimilitud ya no se puede descomponer en una suma que separe los parámetros a optimizar, . Más aún, la log-verosimilitud que se obtiene es difícil de optimizar debido a su estructura, la cual además provoca que se pierda la log-concavidad que se suele tener para distribuciones sencillas. En consecuencia, los modelos de variable latente por lo general son entrenados utilizando enfoques alternativos al de máxima verosimilitud. Por ejemplo, los VAEs y los modelos de difusión utilizan un enfoque variacional para optimizar una cota inferior de la log-verosimilitud (llamada ELBO), mientras que las GANs utilizan un entrenamiento alternado entre dos modelos que compiten entre sí (de hecho, este tipo de modelos no modela una función de verosimilitud de forma explícita).
Por otro lado, un algoritmo clásico para entrenar un modelo de variable latente genérico es el algoritmo de expectation-maximization (EM), el cual estima las variables latentes a partir de los datos (paso E) y luego realiza inferencia sobre los parámetros usando los valores estimados para las variables latentes (paso M). Otro tipo de modelos, como los modelos basados en energía, reparametrizan la verosimilitud de forma conveniente para luego poder optimizarla sin tener que calcularla de forma explícita, y luego utilizan algoritmos tipo Markov chain Monte Carlo (MCMC) para poder generar muestras.
Relación con teoría de la información
En esta sección se revisará la conexión y equivalencia entre el enfoque de máxima verosimilitud y algunos conceptos principales de la teoría de la información. Para esto, se comenzará construyendo la función de información de Shannon.
Información de Shannon y entropía
De manera intuitiva, se puede definir la información de un evento aleatorio como la cantidad de sorpresa o conocimiento no trivial que reporta el saber que el evento ocurrió. De esta forma, la ocurrencia de un evento poco probable (e.g., hoy hubo un terremoto) es muy informativo, mientras que eventos más comunes o de ocurrencia más esperable (e.g., mañana saldrá el sol) entregan poca información. Para definir formalmente este concepto, se construirá una función (con el conjunto de todos los eventos posibles) que mida la cantidad de información que contiene un evento de acuerdo a su probabilidad de ocurrencia. Para esto, se considerarán los siguientes requisitos naturales sobre la función de información:
La información de un evento solo debe depender de su probabilidad. Es decir, para todo evento , para alguna función continua .
La información debe ser no negativa. Además, es nula solo si el evento es completamente seguro. Es decir, para todo evento , , con igualdad si y solo si .
La información que entrega el saber la ocurrencia de dos eventos independientes es la suma de las informaciones individuales. Es decir, para eventos independientes, se debe cumplir que , donde es el evento de que ocurran los eventos y .
Para encontrar la función correcta se puede comenzar considerando dos eventos independientes, . Por los requisitos 3 y 1:
Por otra parte, como son eventos independientes, también se tiene que . Por lo tanto:
Luego, igualando ambas expresiones para , se observa que la función buscada debe cumplir que para . Una función continua natural que cumple esto es el logaritmo, , para cualquier constante . Más aún, la ecuación funcional de Cauchy permite demostrar que el logaritmo es la única función continua que cumple esta propiedad. Por lo tanto, la definición natural para la información de un evento es , para algún valor apropiado de .
Por otro lado, por el requisito de positividad, y notando que para cualquier evento , necesariamente se debe elegir una constante . Además, considerando esta constante de la forma para , la propiedad de cambio de base de los logaritmos permite definir la función de información de Shannon (para una base fija ) como
donde es un evento cualquiera. Cuando la información se mide en bits, mientras que cuando (constante de Euler), la información se mide en nats. Sin embargo, la base que se utilice es irrelevante ya que las definiciones solo difieren por una constante multiplicativa. En este libro se considerará siempre para trabajar con el logaritmo natural, lo cual es la elección estándar en machine learning.
Teniendo definido el concepto de información de un evento, es posible definir la entropía de una distribución como la información esperada para una variable que sigue dicha distribución:
donde en la última igualdad se asumió que es una variable aleatoria continua. En el caso discreto, en cambio, , si se considera .
Recordando la interpretación de la información de Shannon dada anteriormente, la entropía de una variable aleatoria se puede interpretar como el grado de aleatoriedad o incertidumbre que esta posee. Por ejemplo, para , . Se puede verificar que esta cantidad es máxima cuando (máxima incertidumbre) y es mínima cuando o (no hay incertidumbre). De forma similar, la distribución uniforme es la de máxima entropía (incertidumbre) entre todas las distribuciones con soporte acotado, mientras que la distribución gaussiana es la de máxima incertidumbre entre todas las distribuciones con soporte (y de varianza finita).
Entropía cruzada y divergencia KL
Teniendo definido el concepto de entropía, la entropía cruzada entre dos distribuciones, y , se define como la información esperada de pero cuando se considera la distribución en el cálculo de esperanza y la distribución en el cálculo de información:
Si bien el concepto de entropía cruzada parece menos interpretable que el de entropía, este surge naturalmente cuando se consideran las motivaciones originales de Shannon al introducir la teoría de la información, donde el objetivo principal es poder codificar distintos símbolos (e.g., palabras de un vocabulario) de manera eficiente (símbolos frecuentes se codifican con códigos cortos, mientras que símbolos poco usuales se codifican con códigos más extensos). Bajo esta mirada, el primer teorema de Shannon indica que la entropía indica cuántos bits por símbolo (considerando ) se necesitan en promedio para codificar un mensaje (sin pérdida de información), asumiendo que los símbolos son generados según la distribución . De esta forma, la entropía cruzada corresponde a la cantidad de bits que se requieren (en promedio) para codificar un símbolo cuando el esquema de codificación se optimiza asumiendo que los símbolos siguen una distribución , cuando en realidad siguen una distribución .
Por otro lado, la interpretación de compresibilidad de la entropía cruzada no es estrictamente necesaria en el estudio de redes bayesianas ya que, usualmente, la entropía cruzada solo se menciona por la relación que surge al compararla con la verosimilitud para un conjunto de entrenamiento i.i.d., . En efecto, se puede ver que buscar el estimador de máxima verosimilitud, , equivale a minimizar la entropía cruzada entre la distribución empírica y la distribución del modelo que se está ajustando, . Para ver esto, notar que
por lo que . Por otro lado, recordando que puede ser aproximada mediante una estimación de Monte Carlo usando las muestras de , también se puede considerar el estimador de máxima verosimilitud como una aproximación de la solución del problema .
Por otro lado, retomando la interpretación de la entropía cruzada como la cantidad de bits promedio que requiere codificar un símbolo considerando una distribución cuando en realidad la distribución real es , se puede descomponer la cantidad en un término asociado a la cantidad de información irreducible (asociada a la propia información de ) y en un término asociado al error de considerar como distribución de símbolos a en vez de :
donde es la divergencia de Kullback-Leibler (también llamada entropía relativa) entre y :
Por lo tanto, el operador de Kullback-Leibler puede interpretarse como una medida de discrepancia entre las distribuciones y , donde la comparación se realiza con el cociente . En efecto, si las dos distribuciones son similares, entonces el cociente es cercano a 1, por lo que . En particular, cuando .
Por otro lado, se puede probar que la divergencia de Kullback-Leibler es siempre no negativa (esto se conoce como desigualdad de Gibbs). Más aún, dado que , con una constante independiente de , se puede obtener la siguiente equivalencia al enfoque de máxima verosimilitud:
En resumen, buscar el estimador de máxima verosimilitud resulta ser equivalente a minimizar la entropía cruzada , lo que a su vez resulta ser equivalente a minimizar la divergencia . Por otra parte, si bien la divergencia de Kullback-Leibler puede verse como una medida de discrepancia entre dos distribuciones de probabilidad, no es una función de distancia (o métrica) en el sentido estricto. En particular, no es simétrica () ni cumple la desigualdad triangular (). La siguiente figura muestra cómo cambia el argumento minimizante dependiendo del orden que se utilice para las distribuciones dentro de la divergencia:
Efecto del orden de los argumentos en la divergencia de Kullback-Leibler sobre el argumento minimizante [17].
En particular, para el caso de la izquierda se observa la creencia usual de que optimizar un modelo generativo maximizando la log-verosimilitud fuerza al modelo a capturar todas las modas de la distribución de los datos de entrenamiento.
El hecho de que la divergencia de Kullback-Leibler no sea una distancia no permite aplicar distintos resultados conocidos sobre espacios métricos, lo cual muchas veces es útil para obtener garantías teóricas (e.g., convergencia) sobre los temas estudiados. Además, si bien es posible adaptar la divergencia de Kullback-Leibler para construir la distancia de Jensen-Shannon (la cual aparece en el estudio de las GANs), , esta distancia parece un poco forzada y tampoco tiene muy buenas propiedades como la distancia de Wasserstein, la cual se definirá al revisar algunos tópicos de transporte óptimo. Por otro lado, si bien la divergencia de Kullback-Leibler no es una distancia, sí es una función de divergencia, lo que permitirá definir las -GANs, las cuales pueden verse como una generalización de las GANs para distintos funcionales de optimización.
Ejemplo usando una red neuronal
En esta última subsección se implementará un modelo probabilístico de juguete para poder aproximar un estimador de máxima verosimilitud usando una red neuronal. Las librerías que se usarán son las siguientes:
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as pltComo red bayesiana se usará una mixtura (modelo de variable latente , donde es una variable categórica) de dos componentes gaussianos unidimensionales, es decir:
donde y , mientras que , con un parámetro que indica el peso asignado a cada distribución. En consecuencia:
La siguiente clase Mixture implementa esta red bayesiana, asumiendo todos los parámetros como conocidos:
class Mixture:
def __init__(self, r: float, gaussians: list[tuple[float, float]]) -> None:
self.r = r
self.gaussians = gaussians # (mu_0,sigma_0), (mu_1,sigma_1).
def generate_data(self, n_samples: int = 1000) -> torch.Tensor:
r = torch.full([n_samples], self.r)
z = torch.bernoulli(r)
x = torch.empty(n_samples)
x[z == 0] = torch.normal(*self.gaussians[0], [(z == 0).sum()])
x[z == 1] = torch.normal(*self.gaussians[1], [(z == 1).sum()])
return x
@staticmethod
def p_x(x: torch.Tensor, r: float | torch.Tensor, gaussians: list[tuple[float, float]]) -> torch.Tensor:
mu = gaussians[0][0], gaussians[1][0]
var = gaussians[0][1]**2, gaussians[1][1]**2
p0 = (2*torch.pi*var[0])**(-1/2) * torch.exp(-1/(2*var[0]) * (x-mu[0])**2)
p1 = (2*torch.pi*var[1])**(-1/2) * torch.exp(-1/(2*var[1]) * (x-mu[1])**2)
p = (1 - r) * p0 + r * p1
return pEl método generate_data genera muestras por ancestral sampling: primero decide desde qué clase generará cada muestra (sampleando desde ), y luego genera las muestras observadas desde las respectivas distribuciones gaussianas. En este caso, se utilizarán como parámetros reales a y a , mientras que como prior de clase se fijará . Con estos parámetros fijos, se generarán muestras desde la red bayesiana:
r = 0.8
gaussians = [(-1, 1), (3, 2)]
# Datos:
dataset = Mixture(r, gaussians)
x = dataset.generate_data()
# Gráfico:
x_plot = torch.linspace(min(x), max(x), 1000)
density = Mixture.p_x(x_plot, r, gaussians)
plt.figure(figsize=(8, 5))
plt.plot(x_plot, density)
plt.hist(x, bins=100, density=True, alpha=0.3)
plt.xlabel('x')
plt.ylabel('Densidad')
plt.grid(alpha=0.3)
plt.show()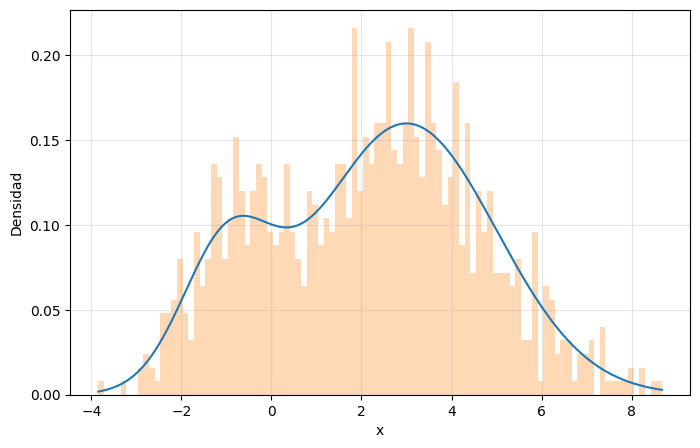
Densidad teórica de la mixtura gaussiana (curva) junto al histograma de las muestras generadas por ancestral sampling.
En el gráfico de las muestras se aplicó KDE, lo que permite, en este caso, identificar claramente los valores de los parámetros y . Para ejemplificar el problema de inferencia, se supondrá que el prior de clase es desconocido, mientras que el resto de parámetros se considerarán conocidos por simplicidad. De esta forma, se usarán las muestras en para inferir el valor del parámetro usando una red neuronal con salida sigmoidal. Notar que la distribución en es incondicional, por lo que la red neuronal no recibe ninguna entrada:
class PriorEstimator(nn.Module):
def __init__(self, init_val: float = 0.5) -> None:
super().__init__()
self.logit_r = nn.Parameter(torch.tensor(init_val))
def forward(self) -> torch.Tensor:
return torch.sigmoid(self.logit_r)La red neuronal será optimizada para maximizar la verosimilitud (usando el método p_x definido en la clase Mixture). Para esto, un detalle importante y que es usado en la práctica es que en vez de maximizar directamente la log-verosimilitud , se suele optimizar la cantidad ya que al normalizar la log-verosimilitud por el tamaño del dataset de entrenamiento, esta cantidad se vuelve independiente de , lo que evita tener que ajustar la tasa de aprendizaje de acuerdo al tamaño de cada dataset (o batch) de entrenamiento:
def train_loop(model: PriorEstimator, optimizer: optim.Optimizer, x: torch.Tensor, n_epochs: int = 500) -> tuple[list[float], list[float]]:
normalized_nlls, r_preds = [], []
for epoch in range(n_epochs):
r_pred = model()
p_x = Mixture.p_x(x, r_pred, gaussians)
normalized_nll = - p_x.log().mean()
optimizer.zero_grad()
normalized_nll.backward()
optimizer.step()
normalized_nlls.append(normalized_nll.item())
r_preds.append(r_pred.item())
return normalized_nlls, r_predsEn la función train_loop se está almacenando y retornando la dinámica de entrenamiento completa para luego poder visualizarla. Para realizar el entrenamiento solo falta instanciar la red neuronal y un optimizador asociado a su único parámetro:
model = PriorEstimator()
optimizer = optim.SGD(model.parameters(), lr=1)
train_loop(model, optimizer, x)
print(f'Estimación: {model().item():.4f}')
print(f'Valor real: {dataset.r}')Estimación: 0.7847 Valor real: 0.8
Se observa que el valor predicho para el parámetro del prior es cercano al valor real. De hecho, la convergencia puede ocurrir en pocas iteraciones, dependiendo de la tasa de aprendizaje que se utilice:
Dinámica de entrenamiento de para distintos valores de la tasa de aprendizaje: evolución de la log-verosimilitud negativa normalizada (columna izquierda) y del parámetro predicho (columna derecha).
Código para la figura.
learning_rates = [0.1, 1, 10, 20, 30] n_rows = len(learning_rates) fig, axes = plt.subplots(n_rows, 2, figsize=(12, n_rows * 4)) for i, lr in enumerate(learning_rates): # Entrenamiento: model = PriorEstimator(init_val=0.1) optimizer = optim.SGD(model.parameters(), lr=lr) normalized_nlls, r_preds = train_loop(model, optimizer, x, n_epochs=100) # Función de pérdida (NLL normalizado): p_x = Mixture.p_x(x, r, gaussians) normalized_nll = - p_x.log().mean() # Gráfico loss: axes[i, 0].axhline(y=normalized_nll, linestyle='--', color='r', alpha=0.7, label='valor real') axes[i, 0].plot(normalized_nlls, label='entrenamiento') axes[i, 0].set_xlabel('Iteración') axes[i, 0].set_ylabel('- log p(x)') axes[i, 0].grid(alpha=0.3) axes[i, 0].set_title(f'log-verosimilitud normalizada (lr={lr})') axes[i, 0].legend() # Gráfico r: axes[i, 1].axhline(y=r, linestyle='--', color='r', alpha=0.7,label='valor real') axes[i, 1].plot(r_preds, label='entrenamiento') axes[i, 1].set_xlabel('Iteración') axes[i, 1].set_ylabel('r predicho') axes[i, 1].grid(alpha=0.3) axes[i, 1].set_title(f'Evolución de r predicho (lr={lr})') axes[i, 1].legend() plt.tight_layout() plt.show()
Se observa que la dinámica de entrenamiento varía considerablemente dependiendo del valor de la tasa de aprendizaje. Una tasa de aprendizaje pequeña puede provocar un entrenamiento lento, mientras que una tasa de aprendizaje muy alta puede provocar una dinámica de entrenamiento muy errática al estar variando demasiado los parámetros en cada iteración. Esto se observa en los últimos gráficos de la columna derecha, donde el parámetro oscila con alta amplitud alrededor del valor real.
Este ejemplo muestra que incluso los modelos generativos de juguete (como este, que es de un solo parámetro) pueden tener una dinámica de entrenamiento inestable si no se ajustan bien los hiperparámetros. En modelos más grandes, este ajuste puede ser aún más delicado, por lo que es usual usar heurísticas para ajustar su valor.
Referencias
- Vaswani, Ashish, Shazeer, Noam, Parmar, Niki, Uszkoreit, Jakob, Jones, Llion, Gomez, Aidan N., Kaiser, Lukasz, Polosukhin, Illia, “Attention Is All You Need”, Advances in Neural Information Processing Systems (NeurIPS), 2017. https://arxiv.org/abs/1706.03762
- Sutskever, Ilya, Vinyals, Oriol, Le, Quoc V., “Sequence to Sequence Learning with Neural Networks”, Advances in Neural Information Processing Systems (NeurIPS), 2014. https://arxiv.org/abs/1409.3215
- Ramesh, Aditya, Pavlov, Mikhail, Goh, Gabriel, Gray, Scott, Voss, Chelsea, Radford, Alec, Chen, Mark, Sutskever, Ilya, “Zero-Shot Text-to-Image Generation”, International Conference on Machine Learning (ICML), 2021. https://arxiv.org/abs/2102.12092
- Rombach, Robin, Blattmann, Andreas, Lorenz, Dominik, Esser, Patrick, Ommer, Björn, “High-Resolution Image Synthesis with Latent Diffusion Models”, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. https://arxiv.org/abs/2112.10752
- Ramesh, Aditya, Dhariwal, Prafulla, Nichol, Alex, Chu, Casey, Chen, Mark, “Hierarchical Text-Conditional Image Generation with CLIP Latents”, arXiv preprint arXiv:2204.06125, 2022. https://arxiv.org/abs/2204.06125
- Betker, James, others, “Improving Image Generation with Better Captions (DALL-E 3)”, 2023. https://cdn.openai.com/papers/dall-e-3.pdf
- Isola, Phillip, Zhu, Jun-Yan, Zhou, Tinghui, Efros, Alexei A., “Image-to-Image Translation with Conditional Adversarial Networks”, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. https://arxiv.org/abs/1611.07004
- Zhu, Jun-Yan, Park, Taesung, Isola, Phillip, Efros, Alexei A., “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”, IEEE International Conference on Computer Vision (ICCV), 2017. https://arxiv.org/abs/1703.10593
- Black Forest Labs, “FLUX.1 Kontext: Flow Matching for In-Context Image Generation”, arXiv preprint arXiv:2506.15742, 2025. https://arxiv.org/abs/2506.15742
- Radford, Alec, Kim, Jong Wook, Xu, Tao, Brockman, Greg, McLeavey, Christine, Sutskever, Ilya, “Robust Speech Recognition via Large-Scale Weak Supervision”, International Conference on Machine Learning (ICML), 2023. https://arxiv.org/abs/2212.04356
- Peebles, William, Xie, Saining, “Scalable Diffusion Models with Transformers”, IEEE/CVF International Conference on Computer Vision (ICCV), 2023. https://arxiv.org/abs/2212.09748
- Perez, Ethan, Strub, Florian, de Vries, Harm, Dumoulin, Vincent, Courville, Aaron, “FiLM: Visual Reasoning with a General Conditioning Layer”, AAAI Conference on Artificial Intelligence, 2018. https://arxiv.org/abs/1709.07871
- Liu, Ziwei, Luo, Ping, Wang, Xiaogang, Tang, Xiaoou, “Large-scale CelebFaces Attributes (CelebA) Dataset”, 2015. https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
- scikit-learn developers, “sklearn.datasets.make\_swiss\_roll”. https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_swiss_roll.html
- Radford, Alec, Metz, Luke, Chintala, Soumith, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”, arXiv preprint arXiv:1511.06434, 2015. https://arxiv.org/abs/1511.06434
- White, Tom, “Sampling Generative Networks”, arXiv preprint arXiv:1609.04468, 2016. https://arxiv.org/abs/1609.04468
- Goodfellow, Ian, Bengio, Yoshua, Courville, Aaron, “Deep Learning”, MIT Press, 2016. https://www.deeplearningbook.org